


VI. Concepts fondamentaux▲
Les scripts montrés dans cette page ne sont plus à exécuter en CLI mais à partir d'un navigateur Web.
VI-A. Fonctionnement d'un script▲
VI-A-1. Introduction▲
Le principe d'exécution d'un script est le suivant : PHP est utilisé par le serveur Apache uniquement pour le code entre balises PHP. Le reste du source est géré directement par Apache ou bien par un autre langage (dotNET, Ruby...) selon le cas.
Ainsi, afficher du code HTML au moyen d'un echo en PHP est une mauvaise solution car cela oblige PHP à traiter quelque chose qu'Apache pourrait faire tout seul :
<?php
/*
Faire ici la récupération des variables $title, $charset et $body
par exemple depuis un formulaire ou une BDD
*/
echo '<?xml version="1.0" encoding="'.$charset.'"?>
<!DOCTYPE html PUBLIC "-//W3C//DTD XHTML 1.0 Strict//EN"
"http://www.w3.org/TR/xhtml1/DTD/xhtml1-strict.dtd">
<html xmlns="http://www.w3.org/1999/xhtml" xml:lang="fr-FR" lang="fr-FR">
<head>
<title>'.$title.'</title>
<meta
http-equiv="content-type"
content="text/html; charset='.$charset.'" />
</head>
<body>
'.$body.'
</body>
</html>';Il est habituellement préférable d'utiliser PHP le moins possible, et de laisser Apache traiter directement un maximum d'affichage :
<?php
/*
Faire ici la récupération des variables $title, $charset et $body
par exemple depuis un formulaire ou une BDD
*/
?>
<?xml version="1.0" encoding="<?php echo $charset; ?>"?>
<!DOCTYPE html PUBLIC "-//W3C//DTD XHTML 1.0 Strict//EN"
"http://www.w3.org/TR/xhtml1/DTD/xhtml1-strict.dtd">
<html xmlns="http://www.w3.org/1999/xhtml" xml:lang="fr-FR" lang="fr-FR">
<head>
<title><?php echo $title; ?></title>
<meta
http-equiv="content-type"
content="text/html; charset=<?php echo $charset; ?>" />
</head>
<body>
<?php echo $body; ?>
</body>
</html>Ici, PHP est appelé cinq fois (dont quatre pour des tâches très courtes), tandis qu'Apache s'occupe de la majorité de l'affichage.
VI-A-2. Contrôle de l'exécution▲
VI-A-2-a. Arrêt du script▲
Un script PHP s'exécute dans un intervalle de temps défini par la variable max_execution_time du fichier de configuration php.ini, dont la valeur vaut 30 secondes par défaut.
max_execution_time = 30Cette valeur peut être modifiée au cours de l'exécution du script par la fonction set_time_limit(). Il est recommandé de ne jamais l'augmenter dans la configuration globale (php.ini) mais plutôt dans les scripts individuels qui en font la demande.
Pour forcer l'arrêt d'un script en cours d'exécution, on peut utiliser les mots clefs die() et exit(). Ce sont des alias, on peut donc utiliser indifféremment l'un ou l'autre. Tous deux acceptent un paramètre optionnel : le message d'erreur à afficher.
VI-A-2-b. Contrôle d'erreurs▲
Toutes les erreurs lancées par PHP dépendent du niveau d'erreur configuré dans le fichier php.ini à la valeur error_reporting.
Voici le niveau d'erreur recommandé en fonction de votre version de PHP :
error_reporting = E_ALL | E_STRICTerror_reporting = E_ALL | E_DEPRECATEDL'affichage des messages d'erreurs est indépendant du niveau de reporting, il est contrôlé par la directive display_errors du php.ini :
display_errors = Ondisplay_errors = OffQuelle que soit votre configuration display_errors, il est fortement recommandé de laisser le paramètre log_errors à "On".
VI-A-3. Contrôle du flux de sortie▲
Avec la configuration par défaut, PHP envoie les données au fur et à mesure qu'il les calcule. Par exemple avec une boucle qui récupère des informations d'une BDD et qui les affiche immédiatement, le navigateur les reçoit petit à petit. C'est parfois pour cela que les pages se chargent par paquets, surtout si la base de données met du temps à répondre à PHP.
Cependant, il est parfois utile de conserver toutes ces informations afin d'effectuer un traitement global avant de les transmettre au navigateur. Cela peut être effectué très simplement au moyen des fonctions de contrôle de flux. Ces fonctions demandent à PHP de conserver dans une variable interne (mémoire tampon) tout ce qu'il veut envoyer à la sortie standard, et d'autres fonctions nous permettent de manipuler ce flux.
Ces fonctions sont rarement utilisées, car cela dénote souvent un problème dans la conception de l'application, c'est une sorte de rustine sur du code mal conçu. C'est le cas de Tidy, qui peut corriger le code HTML avant de l'envoyer au navigateur.
Cependant, il y a des utilisations intéressantes. Le module iconv et l'extension mbstring (que nous verrons plus loin) proposent des fonctions permettant de convertir le charset du texte de la page, en une seule passe au moment d'envoyer le document au navigateur : cela évite d'appeler des fonctions de conversion tout au long du code de l'application.
VI-B. Structure d'un script▲
PHP est souvent décrit comme un moteur de templates. Cela signifie qu'il sert à récupérer des informations et à produire des documents en fonction de ces informations. Dans l'exemple ci-dessus, un document HTML est produit à partir de trois variables. En situation réelle, nous aurions probablement plusieurs accès à une base de données et quelques boucles pour afficher le contenu, filtré et organisé comme il se doit.
- Récupération des informations (+ validation et filtres) ;
- Construction du document (cela peut parfois être fait au moment de l'affichage) ;
- Envoi des en-têtes HTTP (facultatif s'ils sont correctement envoyés par Apache) ;
- Affichage du document.
Retarder l'envoi des en-têtes et l'affichage des informations jusqu'à la fin du script permet de choisir le type de document à afficher et de simplifier le débogage.
Par exemple, avec la même variable $message, on peut produire de nombreux documents totalement différents :
<?php
//récupération des données
$message = empty($_GET['message']) ? 'Hello, world!' : $_GET['message'];
//affichage
header('Content-Type: text/html; charset=iso-8859-1');
?>
<?xml version="1.0" encoding="iso-8859-1"?>
<!DOCTYPE html PUBLIC "-//W3C//DTD XHTML 1.0 Strict//EN"
"http://www.w3.org/TR/xhtml1/DTD/xhtml1-strict.dtd">
<html xmlns="http://www.w3.org/1999/xhtml" xml:lang="fr-FR" lang="fr-FR">
<head>
<title><?php
echo htmlentities($message, ENT_QUOTES, 'iso-8859-1');
?></title>
<meta http-equiv="content-Type" content="text/html; charset=iso-8859-1" />
</head>
<body>
<h1><?php echo htmlentities($message, ENT_QUOTES, 'iso-8859-1'); ?></h1>
</body>
</html><?php
//récupération des données
$message = empty($_GET['message']) ? 'Hello, world!' : $_GET['message'];
//construction du document
$image = imagecreatetruecolor(100, 50);
$text_color = imagecolorallocate($image, 255, 0, 0);
imagestring($image, 1, 5, 5, $message, $text_color);
//affichage
header('Content-Type: image/png');
imagepng($image);<?php
//récupération des données
$message = empty($_GET['message']) ? 'Hello, world!' : $_GET['message'];
//construction du document
$t = new SWFTextField();
$t->setFont(new SWFFont('arial.ttf'));
$t->setColor(255, 0, 0);
$t->addString($message);
$movie = new SWFMovie(7);
$movie->add($t);
//affichage
header('Content-Type: application/x-shockwave-flash');
$movie->output();<?php
//récupération des données
$message = empty($_GET['message']) ? 'Hello, world!' : $_GET['message'];
//construction du document
require 'fpdf.php';
$document = new FPDF();
$document->AddPage();
$document->SetFont('Arial', 'B', 16);
$document->Cell(40, 10, $message);
//affichage
header('Content-Type: application/pdf');
$document->Output();Imaginons maintenant que la variable $message soit remplie au moyen d'un formulaire ou bien d'une base de données. Avec différentes sources de données (formulaire, BDD, etc.), PHP nous permet d'obtenir des documents de types différents (HTML, image, SWF...). Nous pouvons obtenir une sortie en image, HTML, SWF ou d'autres formats tout en conservant le même bloc de code pour la récupération des données. De même, nous pouvons modifier la récupération des données (formulaire, XML, BDD...) tout en conservant le même format de sortie. C'est ce que l'on appelle la modularité, la séparation des couches ou encore l'architecture MVC.
<?php
if(strtolower($_SERVER['REQUEST_METHOD']) == 'post')
{
//récupération des données
$message = $_POST['message'];
//construction du document
$image = imagecreatetruecolor(100, 50);
$text_color = imagecolorallocate($image, 255, 0, 0);
imagestring($image, 1, 5, 5, $message, $text_color);
//affichage
header('Content-Type: image/png');
imagepng($image);
}
else
{
?>
<?xml version="1.0" encoding="utf-8"?>
<!DOCTYPE html PUBLIC "-//W3C//DTD XHTML 1.0 Strict//EN"
"http://www.w3.org/TR/xhtml1/DTD/xhtml1-strict.dtd">
<html xmlns="http://www.w3.org/1999/xhtml" xml:lang="fr-FR" lang="fr-FR">
<head>
<title>New document</title>
<meta http-equiv="content-type" content="text/html; charset=utf-8" />
</head>
<body>
<form method="post" action="<?php echo basename(__FILE__); ?>">
<input type="text" name="message"/>
<input type="submit" value="Générer le bouton"/>
</form>
</body>
</html>
<?php
}<?php
//récupération des données
mysql_connect('host', 'login', 'password');
mysql_select_db('developpez');
$sql = 'SELECT text FROM message HAVING id = max(id) GROUP BY text';
$db_message = mysql_query($sql);
if($tmp = mysql_fetch_assoc($db_message))
{
$message = $tmp['text'];
}
else
{
$message = 'Aucun message';
}
//construction du document
$image = imagecreatetruecolor(100, 50);
$text_color = imagecolorallocate($image, 255, 0, 0);
imagestring($image, 1, 5, 5, $message, $text_color);
//affichage
header('Content-Type: image/png');
imagepng($image);La tâche principale de PHP est donc de récupérer des informations depuis une source externe au script, puis de les afficher dans un format défini. Dans ce cours, nous allons voir comment nous pouvons programmer la récupération des informations depuis différentes sources de données, ainsi que diverses manières de les afficher.
VI-C. Inclure un script dans un autre script▲
VI-C-1. Introduction▲
L'un des aspects qui font de PHP un langage dynamique, est la capacité d'inclure des scripts dans d'autres scripts. Cela permet de "mettre en facteur" des portions de code qui se répètent d'une page à l'autre.
Un exemple simple : index.php, products.php, links.php sont 3 pages du site ayant un en-tête de page et un pied de page identiques.
<?xml version="1.0" encoding="iso-8859-1"?>
<!DOCTYPE html PUBLIC "-//W3C//DTD XHTML 1.0 Strict//EN"
"http://www.w3.org/TR/xhtml1/DTD/xhtml1-strict.dtd">
<html xmlns="http://www.w3.org/1999/xhtml" xml:lang="en-US" lang="en-US">
<head>
<title><?php echo htmlentities($title, ENT_QUOTES, 'iso-8859-1'); ?></title>
<meta http-equiv="content-type" content="text/html; charset=iso-8859-1" />
</head>
<body>
<h1><?php echo htmlentities($title, ENT_QUOTES, 'iso-8859-1'); ?></h1><span class="copyright">Auteur : <?php echo $author; ?>,
<?php echo $date; ?></span>
</body>
</html><?php
$title = 'Accueil';
$author = 'Yogui';
$date = date('Y', filemtime(__FILE__));
include 'header.php';
?>
<p>Bienvenue sur notre site</p>
<p>Notre entreprise fut fondée en...</p>
<?php
include 'footer.php';<?php
$title = 'Nos produits';
$author = 'Yogui';
$date = date('Y', filemtime(__FILE__));
include 'header.php';
?>
<ul>
<li>...</li>
<li>...</li>
<li>...</li>
<li>...</li>
</ul>
<?php
include 'footer.php';<?php
$title = 'Nos partenaires';
$author = 'Yogui';
$date = date('Y', filemtime(__FILE__));
include 'header.php';
?>
<ul>
<li><a href="..." title="...">...</a></li>
<li><a href="..." title="...">...</a></li>
<li><a href="..." title="...">...</a></li>
</ul>
<?php
include 'footer.php';Une autre utilisation classique des inclusions est de séparer les fonctions, les classes, etc. : chaque script regroupe ces éléments par thème. Les conventions préconisent notamment de ne déclarer qu'une seule classe PHP par script.
Exemple :
<?php
function html($string)
{
return utf8_encode(htmlspecialchars($string, ENT_QUOTES));
}VI-C-2. Les instructions include, include_once, require et require_once▲
- include() : Inclure le code du script indiqué, lancer un avertissement si le fichier est introuvable ;
- require() : Inclure le code du script indiqué, lancer une erreur fatale si le fichier est introuvable ;
Chacune de ces instructions se décline en une instruction *_once() qui oblige PHP à vérifier si le script demandé a déjà été inclus au cours de la requête actuelle (très pratique pour les déclarations de fonctions et de classes). Les fonctions *_once() ne sont pas nécessairement plus lentes à l'exécution que leurs grandes soeurs, mais elles consomment légèrement plus de mémoire. La différence étant dérisoire, il est inutile de s'en soucier.
Ainsi, ce script inclut deux fois "header.php" :
Tandis que celui-ci ne l'inclut qu'une seule fois :
<?php
include_once 'header.php';
include_once 'header.php';
include_once 'header.php';
include_once 'header.php';
include_once 'header.php';VI-C-3. Chargement automatique de classes (inclusion implicite)▲
Une fonction particulièrement utile pour les classes est __autoload(). Si cette fonction magique est déclarée dans vos scripts, alors toute classe utilisée mais n'ayant pas été chargée jusque-là, est chargée à l'aide de cette fonction.
<?php
function __autoload($class)
{
require_once $class.'.php';
}
$object = new MyClass(); //chargement automatique de "MyClass.php"<?php
function __autoload($class)
{
require_once str_replace('_', '/', $class).'.php';
}
//chargement automatique de "My/Special/Class.php"
$object = new My_Special_Class();Puisque nous avons fréquemment besoin de plusieurs bibliothèques dans un même projet, et que chaque bibliothèque a toutes les chances de définir son propre __autoload(), nous avons besoin d'un moyen de faire fonctionner tous ces __autoload() en même temps. C'est la SPL qui nous donne la fonction à utiliser : spl_autoload_register()
<?php
spl_autoload_register('basic_autoload');
spl_autoload_register('dotted_autoload');
spl_autoload_register('pear_autoload');
$object = new My_Special_Class();
function basic_autoload($class)
{
$file = $class.'.php';
if(file_exists($file))
{
require_once $file;
}
//echo $file.'<br/>';
}
function dotted_autoload($class)
{
$file = str_replace('_', '.', $class).'.php';
if(file_exists($file))
{
require_once $file;
}
//echo $file.'<br/>';
}
function pear_autoload($class)
{
$file = str_replace('_', '/', $class).'.php';
if(file_exists($file))
{
require_once $file;
}
//echo $file.'<br/>';
}Enlevez les commentaires pour savoir ce qu'il se passe pendant l'exécution du script.
Le chargement automatique de classes ralentit l'exécution du codeCommentaire de Rasmus Lerdorf. Pour améliorer les performances, il faut utiliser un optimiseur de code ainsi qu'un cache d'opcode. Nous reviendrons sur ces notions par la suite.
VI-C-4. Dangers▲
Faites attention lorsque vous utilisez des scripts écrits par d'autres développeurs, qu'ils n'introduisent pas des failles de sécurité dans votre application. De même, évitez d'inclure des scripts situés sur d'autres serveurs car vous n'en avez pas le contrôle, ils peuvent être dangereux.
VI-C-5. Bonnes pratiques▲
Il faut faire très attention à ce qui est mis à disposition sur le Web, car il est parfaitement impossible de faire oublier quelque chose à Internet. Dès lors qu'un document est disponible sur Internet, il est potentiellement déjà repris par Google (et mis en cache), des bots spammeurs, WebArchive.com... Il est futile de croire que l'on peut "supprimer" un document qui a été mis en ligne (même pour très peu de temps), et par conséquent il faut apporter un soin minutieux à ce qui peut être mis en ligne et à ce qui doit rester hors ligne.
À cet effet, les scripts destinés à être inclus ne doivent jamais être placés dans un répertoire du serveur Web accessible depuis Internet, même si vous n'en diffusez jamais l'adresse. Ne croyez jamais que les utilisateurs ne devineront pas l'URL puisque vous ne l'avez pas devinée, ce serait sous estimer le hasard, les pirates, ou simplement notre capacité inhérente à faire des erreurs... La solution la plus sûre est toujours de ne pas tenter le diable, et ici cela se traduit par "ne pas mettre en ligne des fichiers qui n'ont pas besoin de l'être". Apprenez à maîtriser votre serveur Web (le système hôte comme le daemon HTTP), à inclure depuis PHP des fichiers qui ne sont accessibles que par le système de fichiers et non par Internet, etc.
- /web/offline-shared : Les bibliothèques PHP (PEAR, Zend Framework, FPDF...) ;
- /web/offline-sites : Les classes métier spécifiques à chaque application (classes dérivées, scripts communs...) ;
- /web/online-http : Scripts PHP, images, scripts JS etc. accessibles en ligne.
Bien entendu, dans le même ordre d'idées, le SGBD doit être configuré pour que seul votre réseau local, voire quelques machines précises, puissent s'y connecter.
Apprenez à utiliser la directive "include_path" de votre fichier php.ini afin de ne pas surcharger vos scripts de chemins absolus :
<?php
set_include_path('.'
. PATH_SEPARATOR . '/web/offline-shared'
. PATH_SEPARATOR . '/web/offline-sites/test'
. PATH_SEPARATOR . get_include_path());
//situé dans "/web/offline-sites/test/config.php"
include 'config.php';
//situé dans "/web/offline-shared/session-start.php"
include 'session-start.php';
//situé dans "/web/offline-sites/test/header.php"
include 'header.php';Prenez garde aux noms des scripts (collisions) et à l'ordre des inclusions.
La fonction __autoload() est utile uniquement si spl_autoload_register() n'est pas appelée. Dès lors que spl_autoload_register() est appelée dans le code, __autoload() perd sa propriété magique et il faut appeler spl_autoload_register('__autoload'), ce qui est sémantiquement absurde. Par conséquent, il est préférable d'éviter d'utiliser __autoload() seul, au profit de spl_autoload_register(). Cela vous évitera des surprises en utilisant des bibliothèques développées par d'autres personnes ou en distribuant vos propres bibliothèques.
Les déclinaisons *_once() sont prévues pour les scripts qui ne sont nécessaires qu'une fois, par exemple un script de déclarations de fonctions ou de classe. C'est le besoin le plus fréquent, require() et include() sont donc moins souvent utilisables que leurs équivalents *_once().
Il faut utiliser les instructions include et include_once lorsque le script à inclure n'est pas primordial pour le bon fonctionnement du reste du programme, et les instructions require et require_once dans le cas contraire.
<?php
require_once 'config.php';
require_once 'functions.php';
include_once 'header.php';
...
include_once 'footer.php';VI-D. Sécurité au niveau du script▲
VI-D-1. Introduction▲
La majorité des utilisateurs de notre application sont légitimes, ils utilisent simplement l'interface que nous leur proposons. Cependant, certains d'entre eux font des erreurs de manipulation innocentes et d'autres cherchent à s'approprier des droits d'accès plus élevés (piratage). Ces situations peuvent être désastreuses pour notre application, nos données et nos utilisateurs.
En aucun cas il ne faut faire confiance à une donnée provenant d'un utilisateur. Cela implique simplement de vérifier ces données avant de les utiliser, mais il faut le faire systématiquement.
Par exemple, si nous utilisons une variable non validée dans une requête SQL, nous sommes exposés à une faille d'injection SQL.
- Lors de la récupération des données, il convient de les valider et/ou de les filtrer (input validation) ;
- Lors de leur utilisation, il faut les convertir dans le format de sortie (output escaping).
Si ces deux principes ne sont pas scrupuleusement respectés, vous avez toutes les chances de vous faire pirater
Valider des informations revient à s'assurer que les variables contiennent ce qu'elles devraient contenir (leur valeur correspond à un schéma défini). La validation d'un schéma XML à l'aide d'un schéma XSD est un parfait exemple.
Filtrer les données, c'est éliminer le danger dans les variables qui ne passent pas la validation. Le filtrage des données survient donc en cas d'échec (ou à la place) de la validation.
VI-D-2. Validation des données▲
Il faut toujours vérifier le type d'une variable. Bien sûr, le protocole HTTP transmet uniquement du texte et PHP est un langage faiblement typé. Nous avons vu ce genre de code dans la partie sur les types de données :
On ne peut pas compter sur les fonctions is_*() car elles sont trop restrictives. Voici des exemples plus exacts :
<?php
if(!empty($_GET['id']) and ctype_digit($_GET['id']))
{
//"id" est de type numérique entier
}
else
{
//nombre invalide, agir en conséquence
}<?php
if(!empty($_POST['password']) and ctype_print($_POST['password']))
{
//"password" contient uniquement des caractères imprimables
}
else
{
//mot de passe impossible, agir en conséquence :
//par exemple proposer un mot de passe aléatoire
}Les fonctions ctype_*()Comment vérifier le type d'une chaîne en PHP ? sont un très bon moyen de vérifier le type d'une donnée. Si le type attendu est une chaîne, alors il faut souvent effectuer un contrôle plus poussé au moyen d'expressions rationnellesLes regex en PHP.
La validation doit être appliquée à toutes les données provenant de l'extérieur du programme, que ce soit d'un formulaire, d'une variable superglobale, d'un fichier (même s'il est placé sur le serveur), d'une base de données, etc. Toute variable utilisée sans avoir été validée dans le script est un risque pour le reste de l'application, pour votre base de données, pour vos données client...
Les fichiers transmis par des utilisateurs sont à considérer avec autant de vigilence. La validation d'un fichier se fait raisonablement par son type. Ne vous fiez ni à l'extension du fichier, ni au type fourni fans le tableau $_FILES puisque ce sont des informations transmises par le navigateur : s'il s'agit d'un piratage, ces informations sont sans doute falsifiées pour vous induire en erreur. Le type MIME d'un fichier peut être déterminé grâce à l'extension Fileinfo.
VI-D-3. Filtrage des données▲
Si la validation échoue, il faut filtrer les données afin qu'elles correspondent au type et au contenu attendus. Cela se fait au moyen du transtypage pour les types autres que les chaînes, ou avec des expressions rationnelles pour les chaînes.
Dans le cas de nombres entiers (qui constituent la majorité des valeurs transmises par l'utilisateur), le plus simple est le transtypage systématique :
<?php
if(empty($_GET['id']))
{
$id = 0;
}
else
{
$id = (int)$_GET['id']; //on transtype "id" au type numérique entier
}Pour certains types de données complexes et pour les fichiers, si la validation échoue, alors il peut être judicieux d'arrêter le script plutôt que d'essayer de filtrer la valeur. Par exemple pour un document XML, il est parfois impossible (ou trop complexe) de reconstruire un document qui puisse remplacer le document invalide.
Chris Shiflett, expert sécurité, propose de mettre les variables filtrées dans un tableau PHP afin de mettre en valeur le fait qu'elles sont filtrées :
<?php
$clean = array();
if(empty($_GET['id']))
{
$clean['id'] = 0;
}
else
{
//on transtype "id" au type numérique entier
$clean['id'] = (int)$_GET['id'];
}Une variable filtrée ne doit pas pour autant être utilisée sans précautions. On sait simplement que sa valeur correspond à ce que l'on en attend, par exemple ce n'est pas un mot de passe à la place d'un identifiant numérique. L'utilisation de la variable est une autre histoire, elle dépend du contexte de destination.
VI-D-4. Utilisation des données▲
Lors de l'utilisation d'une donnée (affichage, envoi dans une requête SQL ou dans une commande shell...), il faut systématiquement protéger la valeur, la convertir dans le format attendu par le destinataire.
- utf8_encode() : Pour afficher au format UTF-8 (approche recommandée pour les chaînes UTF-8) ;
- htmlentities() : Pour convertir tous les caractères en leur entité HTML correspondante, attention à bien utiliser les deux paramètres optionnels ;
- htmlspecialchars() : Pour convertir uniquement les entités HTML fondamentales (fonction insuffisante si elle est utilisée seule).
<?php
$string = "Developpez.com, le club des développeurs.";
header('Content-Type: text/html; charset=iso-8859-1');
echo htmlentities($string, ENT_QUOTES, 'iso-8859-1');Developpez.com, le club des développeurs.
Une notion fondamentale en sécurité Web est la faille XSS (cross-site scripting). Il s'agit simplement de tromper l'utilisateur et de lui faire exécuter du code destiné à un autre site. C'est possible si une variable utilisateur est affichée sans protection, par exemple avec echo $_GET['login'] on peut facilement produire une faille XSS.
Comment se protéger de la faille XSS ?
La seconde notion fondamentale est la faille CSRF (cross-site request forgery), légèrement plus complexe à mettre en place que XSS du point de vue du pirate, mais elle est également très facile à éviter pour le développeur du site. Nous y reviendrons en parlant des formulaires.
Dans le cas d'attaques XSS ou CSRF, les utilisateurs de votre site sont des victimes à 100%. Ils ne savent pas ce qu'il se passe avant qu'il soit trop tard (en supposant qu'ils le sachent un jour).
Les autres menaces principales au moment de l'utilisation des variables sont des "failles d'injection".
- Comment se protéger des failles d'injection ?
- Développement web : Généralités sur la sécurité, par Julien Pauli
Dans le cas d'une requête SQL, le meilleur moyen est d'utiliser des requêtes préparées : on ne traite alors plus des chaînes mais leur représentation hexadécimale (donc inoffensive).
- MySQLi : $db->prepare()
- PDO : $db->prepare()
VI-D-5. Dangers▲
Faites bien attention à ne jamais utiliser une variable non filtrée ou non validée. La majorité des failles de sécurité sont dues à cette erreur.
VI-D-6. Bonnes pratiques▲
- Une approche de type "poka-yoké" vous évite d'utiliser une donnée sans utiliser une méthode explicite de filtrage ;
- Une extension PHP comme GRASPCORE GRASP ou celle proposée par Wietse VenemaTaint support for PHP.
Comme le dit très bien M. Wietse, aucune extension ne pourra vous dire dans 100% des cas et avec 100% de certitude, que vous avez ou n'avez pas protégé correctement vos données. Les outils sus mentionnés sont des aides pour développer avec le moins d'erreurs possibles, mais c'est aussi votre rôle de programmeur d'auditer votre code.
Dans un monde idéal, ne stockez jamais une valeur "untainted", par exemple le résultat de htmlentities(). Il est préférable de l'utiliser directement dans la fonction de destination, par exemple echo ou mysql_query(). Cela permet de rester conscient du fait qu'une donnée est convertir selon son contexte.
<?php
/*
* connexion au SGBD...
*/
$clean = array();
$clean['login'] = htmlspecialchars($_POST['login'], ENT_QUOTES);
//possibilité d'injection SQL
$db->query(sprintf(
"SELECT id, name FROM user WHERE name='%s'",
$clean['login']));Le code ci-dessus présente deux erreurs : d'une part la valeur n'est pas protégée au format SQL ("escape" ou requête préparée), et d'autre part ce qui est enregistré dans la BDD est vraisemblablement un format HTML plutôt qu'une représentation brute. Ce dernier point est une erreur fondamentale d'analyse des besoins : n'enregistrez jamais la conversion d'un texte, à moins d'enregistrer également la version brute.
VI-E. En-têtes HTTP (headers)▲
VI-E-1. Introduction▲
Lorsqu'un client demande une page Web, c'est-à-dire lorsqu'un internaute clique sur un lien ou valide une adresse dans son navigateur, il envoie une requête HTTP au serveur Web. Le protocole HTTP est décliné en plusieurs versions : celles qui sont le plus couramment utilisées sur le Web sont la 1.0 et la 1.1, et sont décrites en détail par Mathieu LemoineLe Protocole HTTP.
GET /cours/ HTTP/1.1
Host: example.org
User-Agent: Mozilla/1.4
Accept: text/xml, image/png, image/jpeg, image/gif, */*Lorsque le serveur Web reçoit une telle demande, il évalue comment il peut y répondre (quel code HTTP renvoyer), puis il construit la réponse et il envoie le tout.
HTTP/1.1 200 OK
Content-Length: 61
<html>
<body>
<img src="http://example.org/image.png" />
</body>
</html>On voit très bien ici que la réponse HTTP et la page demandée font partie du même envoi. Le serveur Web envoie le code réponse HTTP et le document à la suite l'un de l'autre, comme s'il s'agissait d'un seul document. Les en-têtes HTTP ne peuvent pas être dissociés du document de réponse, ils ne peuvent être envoyés ni au milieu du document ni en plusieurs parties. L'ensemble des en-têtes HTTP doivent donc être prêts avant que le serveur commence à envoyer le document au navigateur qui en a fait la demande.
C'est pour cela qu'utiliser la fonction header() après avoir commencé à envoyer du contenu, mène à l'erreur "headers already sent". Tout ce qui est echo, print, var_dump, print_r etc. sert à transmettre des informations au client, il faut donc terminer l'envoi des en-têtes avant de les utiliser.
C'est aussi pour cela qu'il est impossible d'envoyer deux documents différents en une seule réponse. Une réponse HTTP a un type unique. Lorsqu'une page Web contient des images, des feuilles de style, des animations Flash, des scripts Javascript etc., le serveur envoie chaque élément dans une réponse HTTP séparée, chacun à la demande du navigateur. Le navigateur détermine les éléments à demander au serveur en fonction du document HTML qu'il reçoit ainsi que des préférences de l'utilisateur (ie. désactiver JavaScript ou ne pas afficher d'images), et chaque demande se fait sous la forme d'une requête HTTP.
- Construction du document demandé ;
- Envoi des en-têtes HTTP ;
- Envoi du document.
Sous Apache, vous pouvez voir l'ensemble des transactions HTTP entre un navigateur et votre serveur Web dans le fichier apache/logs/access.log. C'est une excellente source d'informations pour un administrateur consciencieux, et vous devriez fréquemment analyser ce fichier log.
VI-E-2. Quand faut-il envoyer les en-têtes ?▲
Des en-têtes doivent être envoyés à chaque transaction. Le serveur Web est généralement configuré pour envoyer certains en-têtes par défaut, mais le développeur peut les remplacer ou les compléter s'il le juge nécessaire.
Le fichier php.ini dispose par exemple de deux directives default_mimetype et default_charset, qui permettent de définir un type par défaut de contenu et son jeu de caractères. La première est habituellement laissée à "text/html", tandis que la deuxième est généralement mise de côté. En effet, la majorité des requêtes concernent des pages Web au format texte/html, mais pour les autres requêtes le jeu de caractères n'a probablement pas de sens.
L'envoi explicite d'en-têtes depuis le code PHP n'est donc pas systématiquement nécessaire. Le serveur Web se charge de transmettre l'en-tête suivant dans la majorité des cas :
HTTP/1.1 200 OK
Content-Type: text/htmlLe document doit alors correspondre à cet en-tête afin que le navigateur puisse l'interpréter. Par exemple, il serait mal venu d'envoyer une image avec ce Content-Type... C'est ici qu'intervient la fonction header() en PHP.
La fonction header() permet d'envoyer un en-tête HTTP brut, en remplaçant un en-tête précédent similaire. Nous savons que le serveur Web envoie systématiquement le Content-Type text/html, mais si nous avons le code suivant, cet en-tête sera remplacé par le nôtre :
<?php
header('Content-Type: image/png');HTTP/1.1 200 OK
Content-Type: image/pngNous pouvons ainsi dire au navigateur de l'internaute quel est le type exact du contenu que nous lui envoyons. C'est de cette manière que l'on évite les problèmes d'accents, force le téléchargement d'un fichier, évite la mise en cache du document, etc.
À titre d'illustration, voici une requête complète sur une page générant une erreur PHP :
<?php
header('HTTP/1.1 500 Internal Server Error');GET /tests/error.php HTTP/1.1
Host: localhost
User-Agent: Mozilla/5.0 (Windows; U; Windows NT 5.1; en-US; rv:1.8.1.11)
Gecko/20071127 Firefox/2.0.0.11
Accept: text/xml,application/xml,application/xhtml+xml,text/html;
q=0.9,text/plain;q=0.8,image/png,*/*;q=0.5
Accept-Language: en-us,en;q=0.5
Accept-Encoding: gzip,deflate
Accept-Charset: ISO-8859-1,utf-8;q=0.7,*;q=0.7
Keep-Alive: 300
Connection: keep-alive
Cache-Control: max-age=0HTTP/1.x 500 Internal Server Error
Date: Mon, 31 Dec 2007 22:41:19 GMT
Server: Apache/2.2.4 (Win32)
Content-Length: 535
Connection: close
Content-Type: text/html; charset=iso-8859-1HTTP/1.x 500 Internal Server Error
Date: Mon, 31 Dec 2007 22:39:42 GMT
Server: Apache/2.2.4 (Win32) PHP/5.3.0-dev
X-Powered-By: PHP/5.3.0-dev
Content-Length: 0
Connection: close
Content-Type: text/htmlHTTP/1.x 500 Internal Server Error
Date: Mon, 31 Dec 2007 22:40:04 GMT
Server: Apache/1.3.35 (Win32) PHP/5.2.5
X-Powered-By: PHP/5.2.5
Connection: close
Transfer-Encoding: chunked
Content-Type: text/htmlVI-E-3. Dangers▲
Prenez garde aux injections de headers si vous utilisez des variables utilisateur dans vos en-têtes. Il est très facile d'injecter un en-tête dans une application qui ne se protège pas, et cela peut avoir des conséquences dramatiques pour vos utilisateurs. Cette mise en garde est valable aussi bien pour un en-tête HTTP que pour l'en-tête d'un e-mail.
VI-E-4. Bonnes pratiques▲
Si vous êtes sûr de la configuration de votre serveur, n'envoyer que les en-têtes HTTP nécessaires vous fera gagner du temps de développement. Sinon, leur envoi explicite est un bon moyen de vous assurer que le navigateur traite correctement le document qui lui est envoyé dans la suite de la réponse. Le développeur peut s'appuyer sur la configuration du serveur Web, mais il est conseillé d'envoyer des en-têtes personnalisés à chaque réponse HTTP. Renseignez-vous sur le protocole HTTP, sur les particularités des navigateurs Web à ce sujet et souvenez-vous qu'un en-tête HTTP n'est pas perçu comme un ordre par le navigateur, mais plutôt comme un conseil.
Live HTTP Headers est une excellente extension pour Firefox, elle vous permet de voir quels en-têtes sont envoyés ou reçus par votre navigateur.
VI-F. Liens, URLs et paramètres GET▲
VI-F-1. Introduction▲
Les liens sont la plus commune des manières de transmettre une demande de l'utilisateur, et d'introduire du dynamisme dans un site Web.
Sans doute connaissez-vous ce lien :
http://www.google.com/search?hl=en&q=phpSa signification est transparente : charger la page "search" sur le site "google.com", avec les paramètres "hl" en anglais et la question "php".
C'est grâce aux paramètres (à savoir ce qui suit le "?") que Google sait que je veux mes résultats en anglais et pour le mot clef "php". Si je modifie l'un de ces paramètres, Google me répond autre chose.
Les paramètres GET sont mis dans le tableau superglobal $_GET de PHP. C'est un tableau associatif, donc l'exemple ci-dessus se traduit par :
Array
(
[hl] => en
[q] => php
)URL est l'acronyme d'Uniform Resource Locator : cela signifie que, d'un chargement à l'autre de la même URL, le document résultant doit être sensiblement équivalent. On considère les modifications entre deux chargements comme des "mises à jour" et non comme des "contenus différents". L'URL est l'identifiant privilégié pour avoir accès à une ressource. Une URL pointe vers un seul document, et un document n'est accessible que par une seule URL active.
Si vous avez plusieurs URLs pour une même ressource, vous devriez mettre en place au plus vite des redirections HTTP.
La superglobale $_SERVER permet de retrouver la requête originale du navigateur sous diverses formes. Le contenu exact de ce tableau dépend de votre configuration, mais certaines variables se retrouvent, en particulier REQUEST_URI et QUERY_STRING :
http://localhost/tests/error.php?hl=en&q=phpArray
(
[ZendEnablerConfig] => C:/Program Files/Zend/Core/etc/fastcgi.conf
[PHP_FCGI_MAX_REQUESTS] => 10000
[PHP_FCGI_CHILDREN] => 1
[PATH] => /* ma variable système PATH */
[TEMP] => C:\Program Files\Zend\Core\temp
[OS] => Windows_NT
[SystemRoot] => C:\WINDOWS
[ComSpec] => C:\WINDOWS\system32\cmd.exe
[_FCGI_MUTEX_] => 1888
[_FCGI_SHUTDOWN_EVENT_] => 1892
[_FCGI_NTAUTH_IMPERSONATE_] => 1
[FCGI_ROLE] => RESPONDER
[HTTP_HOST] => localhost
[HTTP_USER_AGENT] => Mozilla/5.0 (Windows; U; Windows NT 5.1; en-US;
rv:1.8.1.11) Gecko/20071127 Firefox/2.0.0.11
[HTTP_ACCEPT] => text/xml,application/xml,application/xhtml+xml,text/html;
q=0.9,text/plain;q=0.8,image/png,*/*;q=0.5
[HTTP_ACCEPT_LANGUAGE] => en-us,en;q=0.5
[HTTP_ACCEPT_ENCODING] => gzip,deflate
[HTTP_ACCEPT_CHARSET] => ISO-8859-1,utf-8;q=0.7,*;q=0.7
[HTTP_KEEP_ALIVE] => 300
[HTTP_CONNECTION] => keep-alive
[HTTP_CACHE_CONTROL] => max-age=0
[COMSPEC] => C:\WINDOWS\system32\cmd.exe
[PATHEXT] => .COM;.EXE;.BAT;.CMD;.VBS;.VBE;.JS;.JSE;.WSF;.WSH
[WINDIR] => C:\WINDOWS
[SERVER_SIGNATURE] =>
[SERVER_SOFTWARE] => Apache/2.2.4 (Win32)
[SERVER_NAME] => localhost
[SERVER_ADDR] => 127.0.0.1
[SERVER_PORT] => 80
[REMOTE_ADDR] => 127.0.0.1
[DOCUMENT_ROOT] => C:/Web/online/http
[SERVER_ADMIN] => @@ServerAdmin@@
[SCRIPT_FILENAME] => C:\Web\online\http\tests\error.php
[REMOTE_PORT] => 1125
[GATEWAY_INTERFACE] => CGI/1.1
[SERVER_PROTOCOL] => HTTP/1.1
[REQUEST_METHOD] => GET
[QUERY_STRING] => hl=en&q=php
[REQUEST_URI] => /tests/error.php?hl=en&q=php
[SCRIPT_NAME] => /tests/error.php
[ORIG_SCRIPT_FILENAME] => C:/Web/online/http/tests/error.php
[PHP_SELF] => /tests/error.php
[REQUEST_TIME] => 1199154411
[argv] => Array
(
[0] => hl=en&q=php
)
[argc] => 1
)VI-F-2. Utilisation▲
Afin de simplifier la résolution des problèmes de conversion et de sécurité posés par la transmission de chaînes de caractères, il est préférable de transmettre autant que possible des valeurs numériques. Ces valeurs sont transmises en tant que texte pendant les échanges HTTP, mais elles n'ont aucun encodage spécial et nos scripts peuvent les filtrer sans complications.
Prendez garde à choisir des noms de paramètres utilisant uniquement l'alphabet anglais, des chiffres et pas d'espace, cela simplifie les opérations.
Il reste à parler de l'encodage, mais c'est un sujet qui mérite son propre chapitre.
VI-F-3. Construire une bonne URL▲
Par défaut, le protocole HTTP permet de faire des liens paramétrés que tout langage de script sait interpréter.
http://www.exemple.com/products.php?family=97&manufacturer=46L'un des problèmes de cette approche est que l'URL est relativement laide pour un oeil humain, et par conséquent les humains la lisent rarement. Cela peut même conduire à certaines techniques de phishing, dans la mesure où personne ne fait plus attention au lien sur lequel il clique. Par ailleurs, les moteurs de recherche ont tendance à ne pas référencer toutes les URLs qui leurs semblent dynamiques, car ils savent qu'il y a trop de combinaisons possibles. Enfin, ces mêmes moteurs ne peuvent pas toujours trouver de mots clefs dans une URL dynamique, à cause de la majorité d'identifiants utilisés. Par exemple ci-dessus, "manufacturer" et "family" sont tout à fait inutiles pour le référencement de mon site, alors que le nom de la famille et du constructeur seraient d'une grande aide à la place de leurs identifiants.
Accessoirement, le mot clef "php" est enregistré ici pour une page dans laquelle il n'est aucunement question de PHP ou même de programmation.
Voici un exemple de conséquence : cherchez un podcast ou une conférence PHP sur eMule simplement en tapant "php" avec un type "audio". Vous trouverez de nombreux fichiers nommés "*.php.mp3" car ils ont probablement été téléchargés depuis un script PHP. L'apparition de "php" dans les noms des morceaux n'a aucune valeur mercatique, pourtant il apparaît et cela produit de très nombreux faux résultats dans nos recherches.
Un remède à certains de ces élément pourrait être une URL de ce type :
http://www.exemple.com/products/97/46/Nous n'affichons pas les noms de variables (inutiles pour le référencement), l'URL est plus courte, on n'a pas l'impression d'avoir affaire à des paramètres mais à une arborescence de fichiers HTML statiques. Les avantages semblent être nombreux, mais l'inconvénient majeur est que nous avons peu de mots clefs. L'URL est propre, mais elle est peu efficace : "47" et "96" ne reflètent pas le contenu de ma base de données, ils n'aident pas au référencement de mon site.
Voici une solution vraisemblablement idéale :
http://www.exemple.com/products/processeurs/amd/Si le serveur Web sait interpréter cette URL avec les mêmes paramètres que dans l'exemple précédent, alors elle est bien plus efficace.
Malheureusement, l'un des problèmes de cette approche est que les identifiants sont numériques dans la BDD (contrairement aux chaînes "processeurs" et "amd"), que le nom du fabricant peut être modifié à tout moment (ce qui aurait pour fâcheuse tendance de produire des erreurs 404 partout dans votre site) et que rien n'indique qu'il utilise exclusivement l'alphabet anglais en lettres minuscules (rappelez-vous que ce sont des impératifs pour une bonne URL). Et il y a aussi le problème de l'internationalisation (i18n).
Ainsi, une alternative acceptable (parmi d'autres) peut être :
http://fr.exemple.com/produits/97-processeurs/46-amd/Mais bien sûr, de telles URLs ne correspondent pas à des fichiers sur le serveur Web car c'est impraticable, prend trop de place sur le disque ou bien augmente trop les accès disques. Il faut voir ces URLs comme un moyen virtuel d'avoir accès à une véritable ressource, mais c'est le serveur Web qui s'occupe de l'aspect virtuel (de manière totalement transparente pour l'internaute). Tous les grands serveurs Web du marché savent gérer ce que l'on appelle "URL Rewriting", ou encore "rééciture de liens".
Pour plus de renseignements : Tutoriel d'URL RewritingTutoriel de réécriture de liens en PHP avec Apache
VI-F-4. Construire un bon lien (balise HTML)▲
Construire un lien ne se fait pas à la légère. Renseignez-vous sur le WebmarketingCours et tutoriels de Webmarketing si vous souhaitez approfondir (ce que je vous recommande), mais sachez déjà que le plus important est d'avoir des URLs courtes et d'y mettre des mots clefs. Un lien efficace est uniquement construit par un travail particulièrement soigné.
L'un des aspects passe par le respect des standards. Lisez la documentation concernant le doctype que vous utilisez, que ce soit HTML 4 Transitionnal ou XHTML 1 Strict (pour ne citer que les extrêmes). Dans la plupart des cas, vous aurez affaire aux mêmes éléments du lien : href, title et le texte affiché dans la page. Chacun de ces éléments porte une sémantique précise et différente des autres, il faut donc les utiliser avec dicernement.
Il faut par exemple éviter de négliger la propriété title, qui permet d'ajouter des mots clefs parfois précieux.
Un élément fondamental de la balise lien est bien évidemment la propriété href. Il faut donc y apporter le plus grand soin. Le texte ou le titre d'un lien peuvent changer, mais l'URL (comme son nom l'indique) est un identifiant universel. Il ne faut changer l'URL d'un document qu'après mûre réflexion, et après s'être assuré que l'ancienne URL redirige correctement vers la nouvelle.
VI-F-5. Dangers▲
L'évolution d'un site cause parfois le changement de technologie (par ex. de JSP vers PHP), ce qui a des conséquences parfois dramatiques sur le référencement (erreurs 404 etc.) ; il faut donc à tout prix éviter de montrer l'extension du script dans son URL. Cela permet au serveur de changer de langage de script sans changer l'URL de chacun des documents.
VI-F-6. Bonnes pratiques▲
Demandez-vous ce qu'un utilisateur attentif aimerait voir apparaître dans l'URL comme indicateur de ce que contient le document. Utilisez aussi vos notions de Webmarketing et votre expérience de l'évolution d'un site pour déterminer la meilleure URL pour chaque document.
VI-G. Encodage des caractères▲
VI-G-1. Introduction▲
L'en-tête HTTP "Content-Type" contient un paramètre "charset". La valeur de ce paramètre permet au navigateur de savoir dans quel jeu de caractères est encodé le document qu'il est en train d'afficher. Par exemple, un document encodé en iso-8859-1 ne peut pas contenir certains caractères accentués dans son code source. Il existe néanmoins des équivalents appelés entités HTML : c'est ce que permet d'obtenir la fonction PHP htmlentities().
Comprendre toute la problématique des jeux de caractères est un travail fastidieux qui ne présente pas un grand intérêt. Chaque jeu de caractères est une représentation informatique des caractères utilisés dans un groupe de langues, par exemple ISO-8859-1 contient suffisamment de caractères pour représenter tous les caractères utilisés dans 24 langues (cf. WikipediaModern languages with complete coverage of their alphabet), ce qui n'est pas l'ensemble des langues au monde. Or nous nous intéressons ici à Internet, espace de rencontre et d'échange de toutes les cultures du monde : chaque site doit être en mesure d'afficher du texte issu de n'importe quelle langue, UTF-8 est donc le choix le plus judicieux à cet effet.
Les autres choix sont UTF-7, envers lequel l'Internet Mail Consortium a émis un avis défavorable ; et UTF-16, dont la représentation interne n'est pas compatible avec les formats antérieurs, ce qui implique de nombreux problèmes de migration des applications.
La fonction htmlspecialchars() permet d'encoder uniquement les caractères ayant une signification en XML (et par conséquent en HTML et en XHTML). La fonction inverse est html_entity_decode() et l'ensemble du jeu de caractères peut être déterminé par la fonction get_html_translation_table() :
<pre><?php
print_r(get_html_translation_table(HTML_SPECIALCHARS, ENT_QUOTES));Array
(
["] => "
['] => '
[<] => <
[>] => >
[&] => &
)La fonction htmlentities() renvoie la représentation HTML de chacun des caractères, donc les mêmes que pour htmlspecialchars() ainsi que les caractères accentués, etc. La fonction inverse est html_entity_decode() et l'ensemble du jeu de caractères peut être déterminé par la fonction get_html_translation_table() :
<pre><?php
print_r(get_html_translation_table(HTML_ENTITIES, ENT_QUOTES));Array
(
[ ] =>
[¡] => ¡
[¢] => ¢
[£] => £
[¤] => ¤
[¥] => ¥
[¦] => ¦
[§] => §
[¨] => ¨
[©] => ©
[ª] => ª
[«] => «
[¬] => ¬
[­] => ­
[®] => ®
[¯] => ¯
[°] => °
[±] => ±
[²] => ²
[³] => ³
[´] => ´
[µ] => µ
[¶] => ¶
[·] => ·
[¸] => ¸
[¹] => ¹
[º] => º
[»] => »
[¼] => ¼
[½] => ½
[¾] => ¾
[¿] => ¿
[À] => À
[Á] => Á
[Â] => Â
[Ã] => Ã
[Ä] => Ä
[Å] => Å
[Æ] => Æ
[Ç] => Ç
[È] => È
[É] => É
[Ê] => Ê
[Ë] => Ë
[Ì] => Ì
[Í] => Í
[Î] => Î
[Ï] => Ï
[Ð] => Ð
[Ñ] => Ñ
[Ò] => Ò
[Ó] => Ó
[Ô] => Ô
[Õ] => Õ
[Ö] => Ö
[×] => ×
[Ø] => Ø
[Ù] => Ù
[Ú] => Ú
[Û] => Û
[Ü] => Ü
[Ý] => Ý
[Þ] => Þ
[ß] => ß
[à] => à
[á] => á
[â] => â
[ã] => ã
[ä] => ä
[å] => å
[æ] => æ
[ç] => ç
[è] => è
[é] => é
[ê] => ê
[ë] => ë
[ì] => ì
[í] => í
[î] => î
[ï] => ï
[ð] => ð
[ñ] => ñ
[ò] => ò
[ó] => ó
[ô] => ô
[õ] => õ
[ö] => ö
[÷] => ÷
[ø] => ø
[ù] => ù
[ú] => ú
[û] => û
[ü] => ü
[ý] => ý
[þ] => þ
[ÿ] => ÿ
["] => "
['] => '
[<] => <
[>] => >
[&] => &
)La fonction utf8_encode(), quant à elle, renvoie une représentation UTF-8 de la chaîne en paramètre. L'encodage en UTF-8 permet de représenter plus de jeux de caractères que les jeux latins. Un jeu de caractères ISO-8859-1 est représenté par un octet, soit 2^8 valeurs possibles. UTF-8 dispose de 4 octets, soit 2^32 caractères possibles (moins les caractères de contrôle).
Prenez soin de toujours encoder les caractères en fonction du format de sortie (HTML ou autre). Ne pas utiliser htmlspecialchars() rend vos visiteurs vulnérables à des attaques XSS, et ne pas utiliser un format d'encodage unique tout au long du document génère des caractères illisibles (cf. quelques chapitres plus loin pour des exemples).
La meilleure tactique est de tout encoder en UTF-8. De cette manière, vous pouvez même afficher dans vos pages des caractères issus de jeux de caractères qui n'ont pas d'équivalent HTML, comme les langages dont l'alphabet n'est pas latin (arabe, chinois, japonais...).
Vous pouvez aussi utiliser htmlentities() sur toutes vos chaînes encodées en UTF-8 car cela produit du HTML indépendant du jeu de caratères, et le navigateur le comprend parfaitement l'encodage HTML. C'est un bon moyen d'éviter les erreurs si vous ne maîtrisez pas totalement le sujet, mais ce n'est pas la solution absolue puisque les jeux de caractères autres que l'UTF-8 ont généralement des lacunes : votre site serait hermétique à certaines langues.
En fait, tout le texte de vos pages Web devrait être affiché de cette manière :
echo utf8_encode(htmlspecialchars($text, ENT_QUOTES));VI-G-2. Encodage du script : système de fichiers▲
Le script lui-même (en tant que fichier) porte un encodage dans le système de fichiers. C'est votre éditeur de code qui vous permet de modifier cet encodage, dont les valeurs les plus courantes sont "ANSI" ou bien "UTF-8".
L'encodage du script influe la manière dont PHP traite les chaînes de caractères présentes dans les scripts eux-mêmes.
Si vous essayez par exemple d'utiliser des caractères japonais dans vos scripts, vous aurez de mauvaises surprises si vos scripts sont encodés en ANSI. Certains EDI sont très confus à cause de cela. Modifiez l'encodage interne du script à "UTF-8" et vous pourrez utiliser les caractères du langage que vous voulez, à l'intérieur de vos scripts.
Ici par exemple, j'essaie de faire tenir le mot "japonais" (en japonais) dans un script encodé en UTF-8 puis en ANSI :
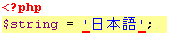
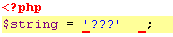
Il semble évident qu'UTF-8 doit être l'encodage de préférence pour vos scripts. Pensez à le préciser de manière bien visible dans la documentation de votre projet.
VI-G-3. Encodage du document : entités HTML▲
L'URL est affichée ainsi dans la barre d'adresse du navigateur :
http://localhost/tests/error.php?hl=en&q=phpPourtant, il faut l'encoder en entités HTML dans le code source HTML :
Pour y parvenir, PHP dispose des fonctions htmlspecialchars() et htmlentities(). La première convertit uniquement les caractères ayant une signification spéciale, tandis que l'autre convertit en entités HTML tous les caractères ayant une correspondance dans le jeu de caractères sélectionné en 3° paramètre.
On peut aussi utiliser la fonction ord() pour convertir du texte brut en texte HTML, mais cela produit des documents bien plus volumineux :
<?php
echo '&#'.ord('a'); //envoie "a" dans le source HTML, que le navigateur affiche "a"La solution la plus efficace est soit d'utiliser htmlentities() avec le bon charset si on sait que le site n'est disponible que dans un certain nombre de langues (ce qui est extrêmement rare), soit d'utiliser htmlspecialchars() en convertissant le texte dans le charset de destination (par exemple UTF-8). Puisqu'htmlentities() ne sait pas gérer toutes les langues au monde, la solution avec htmlspecialchars() est largement meilleure :
<?php
$string = "...Du texte ici...";
header('Content-Type: text/html; charset=utf-8');
echo utf8_encode(htmlspecialchars($string, ENT_QUOTES));VI-G-4. Encodage d'URL : la RFC 3986▲
Un autre aspect à maîtriser est la barre d'adresse du navigateur, qui représente le format des URLs dans les requêtes HTTP. Ce format est défini dans la RFC 3986RFC 3986 - Uniform Resource Identifier (URI): Generic Syntax.
Si je charge l'URL suivante dans mon navigateur, il la traduit avant de la transmettre au serveur Web :
http://localhost/test.php?q=forum cinémaGET /test.php?q=forum%20cin%C3%A9ma HTTP/1.1
Host: localhostIl faut encoder séparément au format "RFC 3986" tous les éléments de la "query string" (donc ici la valeur "forum cinéma"), mais pas le reste de l'URL. D'excellents commentaires de la documentation officielle expliquent très clairement ce qui doit être encodé et avec quelle fonction (urlencode() ou bien rawurlencode()) :
- http://fr2.php.net/manual/fr/function.rawurlencode.php#25182
- http://fr2.php.net/manual/fr/function.rawurlencode.php#26869
- http://fr2.php.net/manual/fr/function.urlencode.php#56426
- http://fr2.php.net/manual/fr/function.urlencode.php#71706
Tous les caractères non alphanumériques et hors "-_." ont un code "URL encoded". Par exemple, le simple mot "cinéma" est encodé ainsi pour une URL (attention à l'encodage interne de votre script, cf. les options de votre éditeur de code) :
<?php
//affiche "forum+cin?ma"
echo urlencode('forum cinéma');
//affiche "forum cin?ma"
echo rawurlencode('forum cinéma');
//affiche "forum+cinéma"
echo urlencode(utf8_encode('forum cinéma'));
//affiche "forum cinéma"
echo rawurlencode(utf8_encode('forum cinéma'));<?php
//affiche "forum+cin?ma"
echo urlencode(utf8_decode('forum cinéma')).'<br/>';
//affiche "forum cin?ma"
echo rawurlencode(utf8_decode('forum cinéma')).'<br/>';
//affiche "forum+cinéma"
echo urlencode('forum cinéma').'<br/>';
//affiche "forum cinéma"
echo rawurlencode('forum cinéma').'<br/>';On voit ici que la représentation interne des caractères du script (encodage du script, ou file encoding) a une incidence sur la représentation "URL encoded". Dans l'idéal, la représentation URL des caractères doit être identique au format d'encodage du document, mais c'est très complexe à mettre en place de manière exacte. Malheureusement, et bien que les navigateurs se débrouillent très bien à ce niveau, leur laisser un peu de liberté débouche trop souvent sur une faille de sécurité (même si la faute est bien souvent du site et non du navigateur). Ma recommandation est de tout encoder au format UTF-8, qui tend à devenir le standard sur Internet. L'arrivée d'Unicode dans PHP6 permettra de clarifier tout cela.
PHP décode automatiquement les caractères encodés selon la RFC 3986 avant le début du script, il est donc rarement nécessaire d'utiliser urldecode().
Les caractères à encoder sont les noms de fichiers, les noms des variables et leurs valeurs. Il ne faut pas encoder "?", "=" et "&" s'ils sont utilisés comme séparateurs, mais uniquement en tant que valeurs.
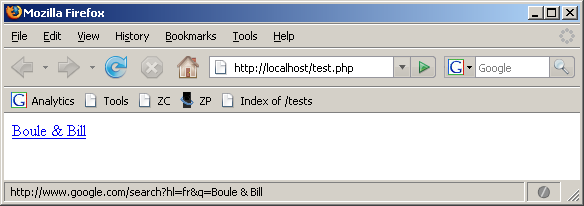
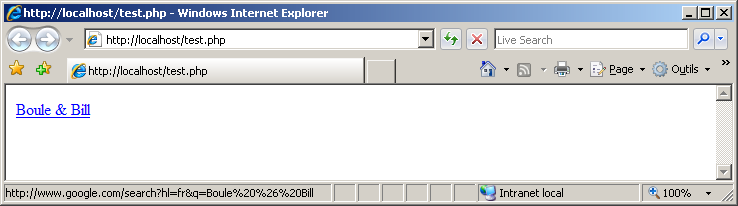
Par exemple, si je souhaite afficher un lien pour une recherche Google à propos de "Boule & Bill", les espaces et le "&" doivent être encodés puisqu'ils ne font pas partie de l'alphabet anglais :
http://www.google.com/search?hl=fr&q=Boule%20%26%20BillVoici un autre exemple avec "E=mc²", où "=" est converti uniquement lorsqu'il est utilisé comme partie de la question :
http://www.google.com/search?hl=en&q=E%3Dmc%C2%B2VI-G-5. Entités HTML + RFC 3986▲
Ne pas confondre l'encodage en vue d'afficher le lien dans une page HTML, et l'encodage en vue de transmettre une requête GET !
Reprenons l'exemple de "Boule & Bill". Je dois convertir ce texte d'abord selon la RFC 3986 puis en entités HTML :
GET /search?hl=fr&q=Boule%20%26%20Bill HTTP/1.1
Host: www.google.com<a
href="http://www.google.com/search?hl=fr&q=Boule%20%26%20Bill"
title="Recherche Google">Boule & Bill</a><?php
//correspond à l'en-tête HTTP (brute) à envoyer
$url = 'http://www.google.com/search?hl='
. rawurlencode('fr') //paramètre à encoder selon la RFC 3986
. '&q='
. rawurlencode('Boule & Bill'); //paramètre à encoder selon la RFC 3986
header('Content-Type: text/html; charset=utf-8');
?>
<a
href="<?php echo html($url);?>"
title="<?php echo html('Recherche Google'); ?>"
><?php echo html('Boule & Bill');?></a>
<?php
function html($string)
{
return utf8_encode(htmlspecialchars($string, ENT_QUOTES));
}- & est la forme brute, elle porte une signification dans la "query string" finale puisqu'elle sépare les paramètres : c'est un séparateur dans l'URL ;
- & est la forme encodée en HTML, qui doit être placée dans la page Web afin que le navigateur la comprenne : elle a une signification HTML ;
- %26 est la forme encodée selon la RFC 3986, elle ne porte aucune signification spéciale ni dans l'URL ni dans le HTML : elle est utilisée seulement en tant que valeur.
Cette méthode ne laisse pas de place aux erreurs, les failles de sécurité sont donc bien plus rares. Prenez garde aux séparateurs car ils peuvent avoir une signification différente (ou ne pas en avoir) selon le contexte, comme "&". Dans l'exemple ci-dessus, la chaîne "Boule & Bill" a été encodée de trois manières successives : une pour chaque contexte. L'ordre d'encodage est de type LIFO.
Certains navigateurs affichent ce lien en texte clair (décodé) dans la barre d'état au passage de la souris, mais transmettent malgré tout l'en-tête encodé.
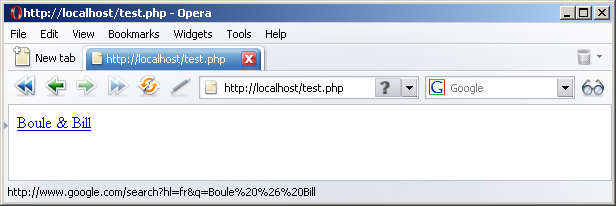
VI-G-6. Exemple d'encodage UTF-8▲
http://localhost/test.php?q=forum+cinéma<?php
header('text/html; charset=utf-8');
?>
<?xml version="1.0" encoding="utf-8"?>
<!DOCTYPE html PUBLIC "-//W3C//DTD XHTML 1.0 Strict//EN"
"http://www.w3.org/TR/xhtml1/DTD/xhtml1-strict.dtd">
<html xmlns="http://www.w3.org/1999/xhtml" xml:lang="fr-FR" lang="fr-FR">
<head>
<title>Test</title>
<meta http-equiv="content-Type" content="text/html; charset=utf-8" />
</head>
<body>
<?php echo htmlentities($_GET['q'], ENT_QUOTES, 'utf-8') ;?>
</body>
</html>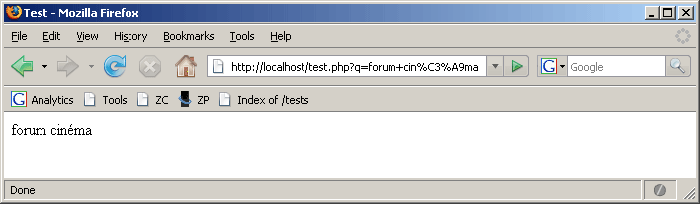
VI-G-7. Exemple d'encodage ISO▲
http://localhost/test.php?q=forum+cin?ma<?php
header('text/html; charset=iso-8859-1');
?>
<?xml version="1.0" encoding="iso-8859-1"?>
<!DOCTYPE html PUBLIC "-//W3C//DTD XHTML 1.0 Strict//EN"
"http://www.w3.org/TR/xhtml1/DTD/xhtml1-strict.dtd">
<html xmlns="http://www.w3.org/1999/xhtml" xml:lang="fr-FR" lang="fr-FR">
<head>
<title>Test</title>
<meta http-equiv="content-Type" content="text/html; charset=iso-8859-1" />
</head>
<body>
<?php echo htmlentities($_GET['q'], ENT_QUOTES, 'iso-8859-1') ;?>
</body>
</html>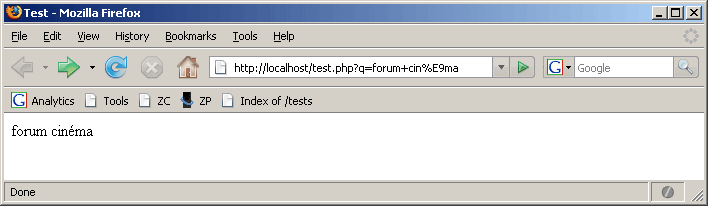
VI-G-8. Exemple de caractères UTF-8 encodés en ISO▲
http://localhost/test.php?q=forum+cinéma<?php
header('text/html; charset=iso-8859-1');
?>
<?xml version="1.0" encoding="iso-8859-1"?>
<!DOCTYPE html PUBLIC "-//W3C//DTD XHTML 1.0 Strict//EN"
"http://www.w3.org/TR/xhtml1/DTD/xhtml1-strict.dtd">
<html xmlns="http://www.w3.org/1999/xhtml" xml:lang="fr-FR" lang="fr-FR">
<head>
<title>Test</title>
<meta http-equiv="content-Type" content="text/html; charset=iso-8859-1" />
</head>
<body>
<?php echo htmlentities($_GET['q'], ENT_QUOTES, 'iso-8859-1') ;?>
</body>
</html>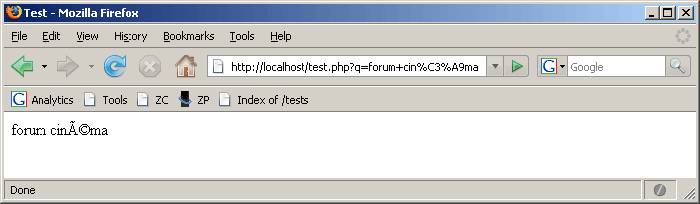
VI-G-9. Exemple de caractères ISO encodés en UTF-8▲
http://localhost/test.php?q=forum+cin?ma<?php
header('text/html; charset=utf-8');
?>
<?xml version="1.0" encoding="utf-8"?>
<!DOCTYPE html PUBLIC "-//W3C//DTD XHTML 1.0 Strict//EN"
"http://www.w3.org/TR/xhtml1/DTD/xhtml1-strict.dtd">
<html xmlns="http://www.w3.org/1999/xhtml" xml:lang="fr-FR" lang="fr-FR">
<head>
<title>Test</title>
<meta http-equiv="content-Type" content="text/html; charset=utf-8" />
</head>
<body>
<?php echo htmlentities($_GET['q'], ENT_QUOTES, 'utf-8') ;?>
</body>
</html>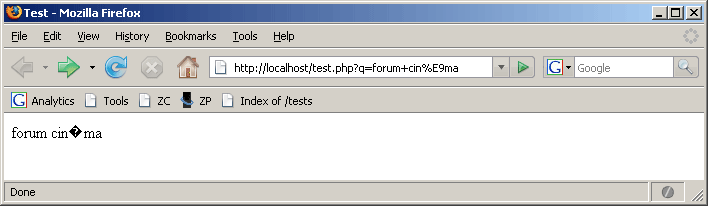
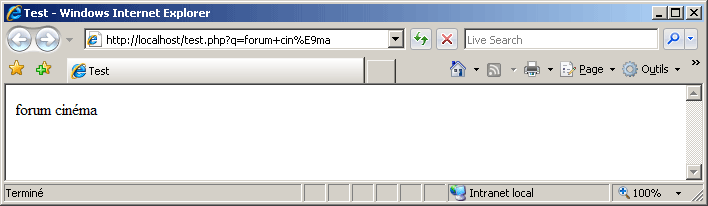
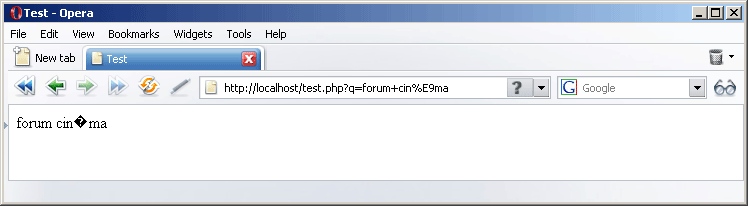
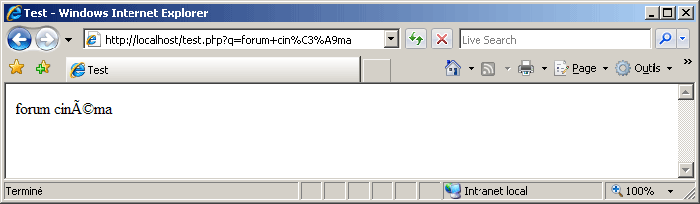
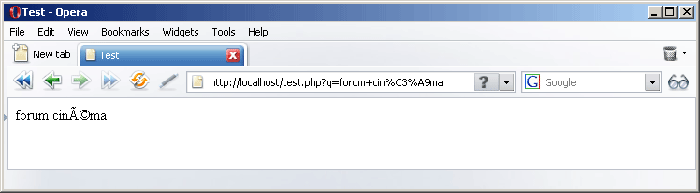
Si, dans cet exemple, Internet Explorer affiche des caractères lisibles, c'est en fait une erreur de sa part puisque le format du document est incorrect. Internet Explorer estime que le format d'encodage est incorrect, et prend la liberté de l'adapter à sa manière. Lucky guess, comme disent les anglophones. En revanche, Firefox et Opera ont raison de ne pas afficher une chaîne lisible. Il me semble d'ailleurs qu'Internet Explorer 6 affichait un simple "?".
VI-G-10. Espace occupé par l'encodage▲
L'un des aspects pris en compte par certains projets pour la sélection du charset, ou plutôt l'un des facteurs qui porte injustement du tort à UTF-8, est la taille de l'encodage des caractères. De nombreuses personnent pensent que, puisqu'UTF-8 est un jeu de caractères multibytes, des documents encodés en UTF-8 prendront nécessairement plus de place qu'en ANSI ou ISO. Cette information n'est pas totalement vraie, et il y a un moyen très simple pour le démontrer.
Le document produit par ce code pèse 36 octets :
<?php
header('Content-Type: text/html; charset=ISO-8859-1');
echo htmlspecialchars('Developpez, le Club des développeurs', ENT_QUOTES);Le document produit par ce code pèse 37 octets :
<?php
header('Content-Type: text/html; charset=UTF-8');
echo utf8_encode(htmlspecialchars(
'Developpez, le Club des développeurs',
ENT_QUOTES));L'exemple ci-dessus montre que tout caractère est encodé le plus bas possible : tous les caractères du jeu ASCII standard sont encodés sur 7 bits ; seul l'accent prend plus d'un octet puisqu'il ne fait pas partie d'ASCII (encodé sur 7 bits) et puisqu'ASCII étendu (encodé sur un octet complet) n'est pas pleinement standardisé ou suivi.
Ainsi, on peut parfaitement encoder intégralement nos documents en UTF-8 sans avoir une taille de fichier excessive. Tous les caractères UTF-8 ne sont pas encodés sur 4 octets, la taille du texte reste donc acceptable. Naturellement, il en va de même pour les bases de données et toutes les autres représentations d'UTF-8.
VI-G-11. Dangers▲
Un document mal encodé est souvent vulnérable à des failles de sécurité comme XSS. Même dans les situations qui ne présentent pas de danger, un document mal encodé n'est pas valide et cela peut amener le navigateur à réagir de manière inattendue. Les captures d'écran fournies ci-dessus en sont un bon exemple.
VI-G-12. Bonnes pratiques▲
Comme nous l'avons vu, le meilleur choix pour présenter des pages Web est d'utiliser un jeu de caractères UTF-8. C'est celui qui offre le panel le plus vaste de caractères, c'est le plus complet des jeux de caractères "multibytes" sans pour autant être très compliqué ou très lourd.
Par ailleurs, nous avons vu qu'il y a plusieurs méthodes pour renseigner le navigateur sur le charset d'une page Web :
default_mimetype = "text/html"
default_charset = "utf-8"<?php
header('Content-Type: text/html; charset=utf-8');<meta http-equiv="content-Type" content="text/html; charset=utf-8" />La configuration du php.ini semble pratique, mais elle n'est pas nécessairement appropriée si l'on utilise des scripts écrits par d'autres personnes, issus d'un autre projet, etc. Il ne faut pas se reposer sur cette configuration puisqu'elle ne correspond pas nécessairement à notre besoin.
Utiliser les deux autres méthodes dans un même document semble redondant, mais il faut prendre en compte certains aspects.
D'une part, transmettre un document HTML depuis le serveur Web vers un navigateur est une chose, et les en-têtes HTTP permettent au navigateur de savoir de quoi il s'agit, mais ils ne persistent pas dans le document une fois qu'il est copié sur une clef USB, dans un e-mail, etc. Il est donc intéressant d'avoir l'information du charset dans le document lui-même, afin que toutes les copies puissent être restituées fidèlement.
D'autre part, il faut prendre en compte la configuration par défaut du serveur Web : si Apache est configuré pour envoyer un charset ISO alors que notre document est encodé en UFT-8, cela produit un conflit et le navigateur Web peut avoir un comportement imprévisible. Utiliser la fonction header() en PHP permet de remplacer l'en-tête envoyé par défaut par Apache, et ainsi de solutionner le problème. Nous ne pouvons pas non plus n'envoyer aucun en-tête par défaut avec Apache, car alors les documents que nous enverrons sans en-tête (sans doute par mégarde ou parce que ce sont des scripts d'une personne tierce qui n'a pas prévu tous ces cas de figure) seront transmis sans aucun en-tête HTTP et sans information sur le type de contenu et l'encodage, ce qui peut avoir un effet désastreux au moment de l'affichage du document.
Il nous faut donc envoyer le type de document et son encodage à la fois au moyen d'en-têtes HTTP et dans une balise META, sans pour autant désactiver la configuration par défaut du serveur Web. Cela fait triple emploi mais c'est la seule solution à toute épreuve.
Utilisez toujours les outils de validationLes meilleurs outils (X)HTML > Validateurs de code pour vérifier que vos documents sont corrects.
Voici une citation de Rasmus Lerdorf pour terminer : "Ultimately we need to get to Unicode everywhereArchives de php.internals".
VI-G-13. Le module iconv▲
Le module iconv est une extension PHP incluse dans le noyau. Son activation a donc lieu lors de la compilation de PHP.
L'un des problèmes d'iconv est son manque de fonctionnalités. L'extension mbstring est bien plus intéressante à ce niveau.
http://localhost/test.php?string=Le club des d?veloppeurs<?php
header('Content-Type: text/html; charset=utf-8');
echo empty($_GET['string']) ?
'' :
iconv('ISO-8859-1', 'UTF-8', $_GET['string']);Le club des développeursIci par exemple, il nous faut savoir avec exactitude le charset des données en entrée. La moindre erreur est ennuyeuse :
Notice: iconv() [function.iconv]: Detected an illegal character
in input string in C:\Web\online\http\test.php on line 2Voici une solution plus élégante mais qui nécessite mbstring :
mbstring.detect_order = ISO-8859-1, UTF-8http://localhost/test.php?string=Le club des d?veloppeurs<?php
header('Content-Type: text/html; charset=utf-8');
echo empty($_GET['string']) ?
'' :
iconv(mb_detect_encoding($_GET['string']), 'UTF-8', $_GET['string']);Le club des développeursBien entendu, il est toujours possible d'utiliser une fonction pour simplifier la procédure :
<?php
header('Content-Type: text/html; charset=utf-8');
echo empty($_GET['string']) ? '' : to_utf8($_GET['string']);
function to_utf8($string)
{
return iconv(mb_detect_encoding($string), 'UTF-8', $string);
}Pour conclure sur iconv, le module me semble peu intéressant, comparé à par exemple l'extension mbstring. En effet, il contraint le développeur soit à utiliser une autre extension pour déterminer le charset des variables (ce qui est absurde, dans la mesure où cette autre extension peut fonctionner seule), soit à savoir exactement de quel encodage est chaque variable (ce qui est totalement utopique dans un environnement Web). Il est possible d'utiliser les headers HTTP envoyés par le navigateur client, mais que se passerait-il si un navigateur malicieux cherchait à faire passer une chaîne UTF-8 pour de l'ISO-8859-1 ? Je crains que cela ouvre l'application à des failles de sécurité...
Cela dit, certaines fonctions d'iconv ont leur utilité, par exemple iconv_mime_decode_headers().
VI-G-14. L'extension mbstring▲
Jusqu'à l'arrivée de PHP 6, le langage PHP n'est pas prévu pour fonctionner nativement avec Unicode. Toutes les opérations classiques sur les chaînes, par exemple strpos() et substr(), ne fonctionnent pas avec les jeux de caractères "multibyte" tel que le japonais. Aucun alphabet non latin ne fonctionne correctement avec ces fonctions.
La bibliothèque mbstring permet de remédier à ce problème. Elle fournit des fonctions alternatives pour les tâches les plus courantes, par exemple mb_strlen() à la place de strlen() ou encore mb_strpos() au lieu de strpos(). Toutes les opérations sur les chaînes ne sont cependant pas disponibles, par exemple l'extension PCRE n'a pas été adaptée.
Voici un exemple de script qui ne fonctionne pas comme on pourrait s'y attendre :

Imaginez que je veuille utiliser substr($string, 0, 2), est-ce que j'obtiendrais les 2 premiers caractères ou bien les 2/3 du premier caractère ? <insert smiley here>
En revanche, la bibliothèque mbstring permet de préciser l'encodage interne des caractères et d'en tenir compte :

Cette fois, si j'utilise mb_substr($string, 0, 2), je suis sûr d'obtenir les 2 premiers caractères du mot.
La plupart des applications Web développées pour nos pays n'ont pas besoin de fonctions de texte aussi complexes. Vous ne devriez considérer l'utilisation de cette extension que si vous en avez réellement besoin, ou peut-être attendre PHP 6 pour uniformiser le comportement des chaînes Unicode.
NB : Les caractères utilisés ci-dessus sont la traduction japonaise du mot "japonais" selon Wikipédia.
Voici un exemple de conversion de chaînes d'entrée :
<?php
mb_internal_encoding('UTF-8');
$variable_1 = to_utf8($variable_1);
$variable_2 = to_utf8($variable_2);
$variable_3 = to_utf8($variable_3);
function to_utf8($string)
{
return mb_convert_variables('UTF-8', mb_detect_encoding($string), $string);
}Vous pouvez aussi utiliser cette autre méthode, moins fastidieuse, qui convertit automatiquement toutes les variables d'entrée :
[mbstring]
mbstring.internal_encoding = UTF-8
mbstring.http_output = UTF-8
mbstring.encoding_translation = On
mbstring.detect_order = auto
mbstring.substitute_character = none
mbstring.strict_encoding = OnVI-G-15. Expressions régulières (PCRE) et Unicode▲
Je ne compte pas entrer ici dans le détail des regex, puisque c'est un sujet trop vaste pour être abordé convenablement en quelques lignes. Cependant, un aspect de PCRE est souvent omis : les fonctions preg_*() peuvent gérer les caractères multibytes à condition de les écrire sous leur forme hexadécimale et d'utiliser le modificateur "u".
Par exemple, pour vérifier qu'un texte fait partie de l'un des trois systèmes d'écriture japonaise, on peut utiliser la regex suivante :
<?php
if(preg_match('/[一-龿]/u', $variable))
{
echo 'Kanji';
}
else if(preg_match('/[぀-ゟ]/u', $variable))
{
echo 'Hiragana';
}
else if(preg_match('/[゠-ヿ]/u', $variable))
{
echo 'Katagana';
}
else
{
echo 'Pas un mot japonais';
}Une chaîne UTF-8 invalide arrête la regex sans rien trouver. Avant d'utiliser ces masques, il est donc nécessaire de suivre quelques conseils, cf. ce commentaire de la documentationRegarding the validity of a UTF-8 string when using the /u pattern modifier.