



V. Maintenance des donnûˋes d'un index▲
Les donnûˋes d'index Solr peuvent ûˆtre mises û jour avec un document au format CSVUpdating a Solr Index with CSV ou XMLUpdating a Solr Index with XML. D'aprû´s le fichier solrconfig.xml d'exemple, les formats javabin et JSONUpdating a Solr Index with JSON sont aussi disponibles mais la documentation û ce sujet est moins abondante et je n'ai pas vûˋrifiûˋ moi-mûˆme. Quel que soit son format, le document doit ûˆtre soumis û Solr via la mûˋthode HTTP POST. Dans les paragraphes suivants, nous allons voir comment le document doit ûˆtre structurûˋ et de quelle maniû´re nous pouvons l'envoyer û Solr.
Le format XML a ma prûˋfûˋrence sur le format CSV car il est plus facile û relire que ce dernier, surtout dans le cas des champs multivaluûˋs. Avec un document CSV, les choses se compliquent dû´s que le texte û indexer contient le caractû´re de sûˋparation de champ ou un saut de ligne (ce qui est une situation plutûÇt courante).
V-A. Configuration nûˋcessaire▲
Afin de pouvoir envoyer des mises û jour de l'index au noyau, il nous faut configurer le noyau avec le requestHandler que nous utiliserons :
<requestHandler name="/update" class="solr.XmlUpdateRequestHandler" />
<requestHandler name="/update/javabin" class="solr.BinaryUpdateRequestHandler" />
<requestHandler name="/update/csv" class="solr.CSVRequestHandler" startup="lazy" />
<requestHandler name="/update/json" class="solr.JsonUpdateRequestHandler" startup="lazy" />Dans la mesure oû¿ il est peu raisonnable de dûˋvelopper et de maintenir plusieurs maniû´res de mettre un index û jour, vous n'aurez probablement besoin que d'un seul requestHandler "update". Ainsi, vous pouvez dûˋclarer uniquement le handler de base "/update" et choisir sa classe Java en fonction de vos besoins :
<requestHandler name="/update" class="solr.XmlUpdateRequestHandler" /><requestHandler name="/update" class="solr.BinaryUpdateRequestHandler" /><requestHandler name="/update" class="solr.CSVRequestHandler" startup="lazy" /><requestHandler name="/update" class="solr.JsonUpdateRequestHandler" startup="lazy" />V-B. Ajout et modification de donnûˋes▲
Le document XML est construit de la maniû´re suivante :
<add>
<doc>
<field name=""></field>
<field name=""></field>
<field name=""></field>
</doc>
<doc>
<field name=""></field>
<field name=""></field>
<field name=""></field>
</doc>
</add>Des exemples plus complets sont distribuûˋs avec Solr (6).
Chaque néud <doc> correspond û un document de l'index. Il contient l'ensemble des champs dûˋfinis dans le fichier schema.xml pour ce noyau.
Les champs dûˋfinis avec l'attribut required="true" dans le schûˋma doivent obligatoirement figurer pour chaque néud <doc>. Un mûˆme champ peut apparaûÛtre plusieurs fois dans le mûˆme néud <doc> s'il s'agit d'un champ multivaluûˋ, c'est-û -dire dûˋfini avec l'attribut multivalued="true" dans le schûˋma. Les autres champs ne peuvent apparaûÛtre qu'une seule fois pour chaque néud <doc>.
Comme nous l'avons vu dans le chapitre prûˋcûˋdent, la contrainte d'unicitûˋ d'un index est le champ dûˋfini comme <uniqueKey> dans le schûˋma. Pour Solr, il n'y a pas de distinction entre les opûˋrations "create" et "update" des documents : lorsque le requestHandler de mise û jour est appelûˋ pour une certaine uniqueKey, Solr s'occupe de crûˋer le document correspondant s'il n'existait pas encore, ou de le modifier s'il existait dûˋjû .
Voici les attributs optionnels pour chaque néud XML du document de mise û jour :
| Néud | Attribut | Valeurs | Description |
|---|---|---|---|
| add | overwrite | true | false | Remplacer les documents ayant la mûˆme uniqueKey Dûˋfaut û "false" |
| add | commitWithin | millisecondes | Valider le document aprû´s ce dûˋlai |
| doc | boost | float | Augmenter la pertinence de ce document complet pour la recherche (si omitNorms="false" dans le schûˋma)
Dûˋfaut û "1.0" |
| field | boost | float | Augmenter la pertinence de ce champ pour la recherche (si omitNorms="false" dans le schûˋma)
Dûˋfaut û "1.0" |
Lors de la configuration des champs de l'index par l'intermûˋdiaire du fichier schema.xml, les champs dûˋclarûˋs comme "dest" de <copyField/> ne doivent pas figurer dans les mises û jour. Par exemple, pour le schûˋma donnûˋ dans cet article, nous pouvons rûˋsumer la liste des champs par le tableau suivant :
| Champ | schema:copyField | schema:field[required] | Prûˋsence dans doc. de mû j |
|---|---|---|---|
| uuid | non dûˋfini | oui | oui, obligatoire |
| productNameEnDisplay | source | non | oui, facultatif |
| productNameFrDisplay | source | non | oui, facultatif |
| productNameEnAutoComplete | dest | non | non |
| productNameFrAutoComplete | dest | non | non |
| productNameEnSearch | dest | non | non |
| productNameFrSearch | dest | non | non |
| manufacturerNameDisplay | source | non | oui, facultatif |
| manufacturerNameAutoComplete | dest | non | non |
| manufacturerNameEnSearch | dest | non | non |
| manufacturerNameFrSearch | dest | non | non |
| allEnSearch | dest | non | non |
| allFrSearch | dest | non | non |
Cela pourrait donner le document XML suivant :
<add>
<doc>
<field name="uuid"></field>
<field name="productNameEnDisplay"></field>
<field name="productNameFrDisplay"></field>
<field name="manufacturerNameDisplay"></field>
</doc>
</add>- productNameEnAutoComplete
- productNameFrAutoComplete
- productNameEnSearch
- productNameFrSearch
- manufacturerNameAutoComplete
- manufacturerNameEnSearch
- manufacturerNameFrSearch
- allEnSearch
- allFrSearch
V-C. Suppression de donnûˋes▲
La suppression de documents d'un index se fait au moyen d'un document delete contenant une combinaison de néuds id et query :
<delete>
<query>*:*</query>
</delete><delete>
<id>05991</id>
</delete><delete>
<id>05991</id>
<id>06000</id>
<query>office:Bridgewater</query>
<query>office:Osaka</query>
</delete>La syntaxe du néud query pour la suppression de donnûˋes est la mûˆme que pour la recherche avec un searchHandler. Nous aborderons cela plus loin dans l'article.
Le nom du néud id est figûˋ, il ne peut pas prendre le nom d'un champ du schûˋma. Solr s'attend û trouver le contenu de ce néud dans le champ dûˋfini comme uniqueKey dans le schûˋma. Pour le schûˋma prûˋsentûˋ dans cet article, les deux requûˆtes suivantes sont ûˋquivalentes :
<delete>
<id>aaaa</id>
</delete><delete>
<query>uuid:aaaa</query>
</delete>V-D. Validation de mises û jour▲
La validation des mises û jour se fait par les commandes suivantes :
<commit/><optimize/>Voici les attributs optionnels du document de mise û jour :
| Néud | Attribut | Valeurs | Description |
|---|---|---|---|
| commit et optimize | waitFlush | true | false | Bloquer jusqu'û ce que les modifications de l'index soient ûˋcrites sur le disque
Dûˋfaut û "true" |
| commit et optimize | waitSearcher | true | false | Bloquer jusqu'û ce qu'un nouveau chercheur soit ouvert et enregistrûˋ comme le chercheur principal, rendant ainsi les modifications visibles
Dûˋfaut û "true" |
| commit | expungeDeletes | true | false | Ignorer les suppressions
Dûˋfaut û "false" |
| optimize | maxSegments | int | Optimiser jusqu'û ce nombre de segments individuels
Dûˋfaut û "1" |
V-E. Annulation de mises û jour▲
La commande rollback permet d'annuler toutes les commandes add et delete depuis la derniû´re commande commit ou optimize :
<rollback/>V-F. Soumettre le document de maintenance▲
L'envoi d'un document de maintenance û Solr se fait via la mûˋthode HTTP POST au requestHandler "update" de notre noyau, par exemple :
http://localhost:8080/solr/CORENAME/update
V-G. Exemple▲
Prûˋparons un XML û envoyer :
<add>
<doc>
<field name="uuid">f2446de21f011a769ec62b4c4ecb96d2</field>
<field name="productNameEnDisplay">Solr, the enterprise search server</field>
<field name="productNameFrDisplay">Solr, le serveur de recherche pour entreprises</field>
<field name="manufacturerNameDisplay">Apache Software Foundation</field>
</doc>
</add>Envoyons ce XML û l'aide de cURL :
curl http://localhost:8080/solr/CORENAME/update -H "Content-Type: text/xml" --data-binary "<delete><query>*:*</query></delete>"
curl http://localhost:8080/solr/CORENAME/update -H "Content-Type: text/xml" --data-binary "INSERER_ICI_TOUT_LE_XML"
curl http://localhost:8080/solr/CORENAME/update -H "Content-Type: text/xml" --data-binary "<optimize waitSearcher='false'/>"cURL est le logiciel habituellement utilisûˋ pour cette dûˋmonstration mais vous n'ûˆtes pas obligûˋs d'y avoir recours. Vous pouvez utiliser le programme de votre choix, voire dûˋvelopper un petit script ou programme avec le langage de votre prûˋfûˋrence.
Le code suivant est un exemple de script PHP pouvant fonctionner avec une installation PHP par dûˋfaut (ni le programme cURL ni l'extension php_curl ne sont nûˋcessaires) :
#!/usr/bin/php5
<?php
if(PHP_SAPI != 'cli')
{
die('error: not sent via CLI'.PHP_EOL);
}
if($argc != 4 or !in_array($argv[2], array('file', 'string')))
{
die('usage is: '.basename(__FILE__).' CORENAME "file"|"string" FILENAME|CONTENTS'.PHP_EOL);
}
list(, $core_name, $content_type, $content) = $argv;
$url = sprintf('http://localhost:8080/solr/%s/update', $core_name);
$data = $content_type == 'string' ? $content : file_get_contents($content);
$params = array
(
'http' => array (
'method' => 'POST'
, 'header' => 'Content-Type: text/xml'
, 'content' => $data
, 'timeout' => 5
)
);
$context = stream_context_create($params);
$result = file_get_contents($url, FALSE, $context);
var_dump($result);
echo 'done'.PHP_EOL;./send.php produits string "<delete><query>*:*</query></delete>"
./send.php produits file add1.xml
./send.php produits string "<optimize waitSearcher='true'/>"php.exe send.php produits string "<delete><query>*:*</query></delete>"
php.exe send.php produits file add1.xml
php.exe send.php produits string "<optimize waitSearcher='true'/>"
Pour vûˋrifier que les modifications ont bien ûˋtûˋ effectuûˋes, vous pouvez charger la page suivante :
http://localhost:8080/solr/admin/cores?core=CORENAME&action=status

Afin de vûˋrifier plus prûˋcisûˋment ce qui a ûˋtûˋ fait par Solr, notamment que les directives copyField ont rûˋussi, voici une requûˆte simple sur l'index :
http://localhost:8080/solr/produits/select?q=uuid:f2446de21f011a769ec62b4c4ecb96d2
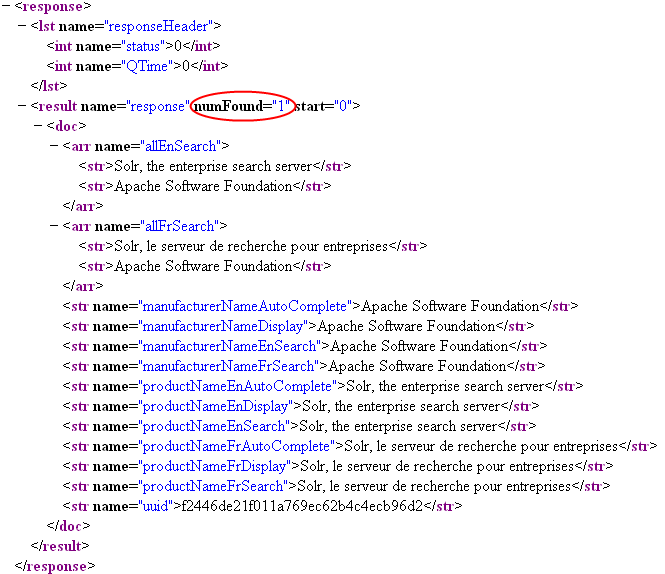
- uuid
- productNameEnDisplay
- productNameFrDisplay
- manufacturerNameDisplay
La capture d'ûˋcran ci-dessus montre que Solr a bel et bien rempli tous les champs de l'index d'aprû´s les rû´gles copyField. Comme prûˋvu, certains champs de l'index contiennent plusieurs valeurs.