


I. Problûˋmatique▲
Faire connaûÛtre son site Web n'est plus suffisant. Il faut aujourd'hui se focaliser sur chaque thû´me abordûˋ par un site, chacune des pages ayant son propre contexte.
Le rûˋfûˋrencement est une bataille de tous les instants dans laquelle ceux qui font attention aux moindres dûˋtails prennent de l'avance sur ceux qui laissent leur site vivre sa vie et sur ceux qui, au contraire, s'en occupent de trop.
Il ne s'agit pas de simplement remplir les balises META de chaque page HTML. Il s'agit de techniques bien plus avancûˋes, plus subtiles, qui sont mûˆme parfois hors de notre contrûÇle.
I-A. Prûˋsentation▲
û l'origine, il y avait des sites. Ils restaient isolûˋs et n'ûˋtaient pas prûˋvus pour le grand public.
Ensuite, les besoins de notoriûˋtûˋ se sont fait sentir. C'est ainsi que sont arrivûˋs les annuaires et les moteurs de recherche.
Il me semble fondamental de situer le contexte avant de rentrer dans le vif du sujet.
I-B. Historique▲
Avant 1993, il ûˋtait difficile de trouver du contenu. Le concept de ô¨ô spiderô ô£ n'existait pas (du moins, pas en tant que programme automatisûˋ permettant de construire des index aussi complets que ceux qui existent aujourd'hui). Chacun conservait une liste de ses sites favoris et l'ûˋchangeait avec les autres internautes. Ce comportement n'a d'ailleurs pas totalement disparu.
GrûÂce û ce systû´me basûˋ sur la confiance, chacun pouvait se reposer en ce qu'un site affirmait contenir au moyen de la fameuse balise META.
En 1995 sont apparus deux majeurs du rûˋfûˋrencement que nous connaissons encore aujourd'huiô : Yahoo! (Yet Another Hierarchical Officious Oracle, ô¨ô encore un oracle officieux et hiûˋrarchiqueô ô£) et AltaVista (ô¨ô vue de hautô ô£, dont les crûˋateurs travaillent maintenant pour Google). Yahoo! organisait les sites selon des thûˋmatiques hiûˋrarchisûˋes, tandis qu'AltaVista prûˋfûˋrait prendre une approche de recherche.
û cette ûˋpoque, le rûˋfûˋrencement ûˋtait fondûˋ sur les informations que chaque webmestre pouvait renseigner dans ses propres pages (balise META). Le propriûˋtaire avait donc un contrûÇle total, permettant de donner des indications arbitraires. C'est un hûˋritage de l'û´re prûˋcûˋdente. Les webmestres commencû´rent ainsi û donner de fausses informations de maniû´re û attirer davantage de visiteurs.
Google est arrivûˋ en 1998 avec une nouvelle mûˋthode de rûˋfûˋrencementô : le PageRank, fondûˋ principalement sur les backlinks. L'idûˋe ûˋtait de trouver un moyen qui permette de dûˋterminer la popularitûˋ d'une page Web et qui soit le critû´re principal pour classer les rûˋsultats d'une recherche.
Le rûˋsultat est explosif, le succû´s fulgurant. Aujourd'hui, Google est incontestablement le moteur de recherche le plus utilisûˋ, mais dont les prûˋdûˋcesseurs ne se laissent pas abattre.
En 2001, Google atteint une popularitûˋ sans prûˋcûˋdent, juste aprû´s que les moteurs de recherche abandonnent les balises META comme critû´res (cet abandon a lieu au dûˋbut du siû´cle).
En 2004 sont lancûˋs les deux concurrents majeurs actuels de Google Searchô : Yahoo! Search et MSN Search (Microsoft).
I-C. Comprendre les moteurs de recherche▲
Le rûˋfûˋrencement est constituûˋ de trois ûˋtapesô :
- Web crawling (ô¨ô parcours du Webô ô£)ô ;
- Indexing (ô¨ô mise û l'index du contenuô ô£)ô ;
- Searching (ô¨ô rechercheô ô£).
Je vous propose, afin de parfaitement comprendre comment fonctionne un spider (la premiû´re ûˋtape), de faire le nûÇtre. N'ayons pas peur, ce n'est pas trû´s complexe.
Notre robot se contentera de lire une page Web et d'en donner la liste des images, du contenu et des liensô ; il suivra quelques-uns de ces liens afin de nous donner des statistiques sur les pages liûˋes, et ce sur quelques niveaux. Un vûˋritable spider devra aller bien plus loin (reproduire cette opûˋration û l'infini), mais nous ne disposons pas d'une puissance de calcul phûˋnomûˋnaleãÎ
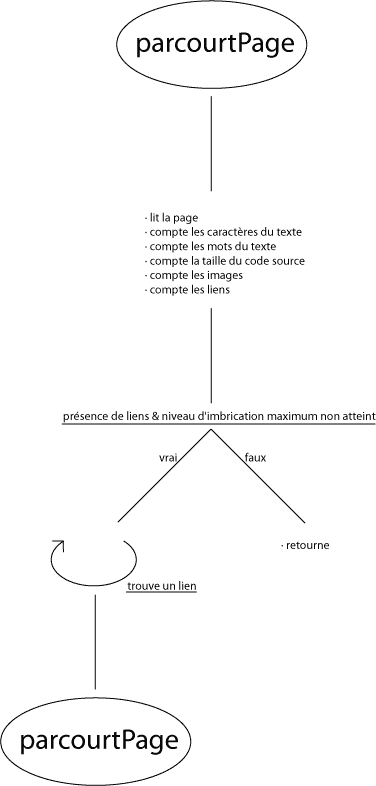
Tûˋlûˋcharger le script (ûˋcrit en PHP)ô : [ ./fichiers/spider.zip ] ou [ https://g-rossolini.developpez.com/tutoriels/seo/fichiers/spider.zip ]
Je ne mets pas ce script en dûˋmonstration, car il est trû´s gourmand en bande passante.
Cet exemple a plusieurs objectifsô : d'une part, vous dûˋmontrer que le spider ne peut pas analyser autre chose que du texte (adieu les images et les animations en Flash)ô ; d'autre part, vous sensibiliser aux ûˋlûˋments qui ont de l'importance dans une page (attributs ô¨ô altô ô£ des images et ô¨ô titleô ô£ des liens, par exempleô : je les ai mis en gras quand ils sont disponibles).
L'ûˋtape de mise û l'index comprend une analyse complû´te du contenu, des liens, du code, etc. C'est ici que l'algorithme entre en jeu et que la plus grosse partie des calculs sont effectuûˋs.
La recherche est une ûˋtape relativement simpleô : il s'agit simplement de trouver (dans l'index) les pages qui correspondent aux termes recherchûˋs, puis de les classer.
I-D. Les techniques▲
Chapeau blanc (ô¨ô white hatô ô£)▲
Ce sont les mûˋthodes honnûˆtes.
Il s'agit des mûˋthodes de SEO permettant simplement de suivre les conseils des moteurs de recherche. Cela vise simplement û construire des sites au contenu utile et correctement mis en valeur.
Exemplesô :
- Sûˋlectionner les mots clefs avec grand soinô ;
- Ne pas trop diversifier les thû´mes traitûˋs par un mûˆme site Webô ;
- Utiliser du code HTML correctô ;
- etc.
Je ne souhaite pas donner davantage de dûˋtails ici puisque cela fera l'objet de divers tutoriels sûˋparûˋs.
Chapeau noir (ô¨ô black hatô ô£)▲
Ce sont les mûˋthodes manipulatrices de rûˋsultats. Je vous les dûˋconseille, car elles ne sont pas pûˋrennesô ; de plus, elles sont ûˋthiquement incorrectes.
Il s'agit des mûˋthodes permettant de manipuler les rûˋsultats de moteurs de recherche en utilisant des failles dans les algorithmes des moteurs. Ces techniques peuvent fonctionner, mais les moteurs de recherche les combattent activement, ce qui laisse penser qu'elles deviennent inefficaces (voire pûˋnalisantes) avec le temps.
En fûˋvrier 2006, Google supprimait de son index les sites de BMW Allemagne et de Ricoh Allemagne pour avoir utilisûˋ ces techniques. Les sites en question ont ûˋvidemment remûˋdiûˋ û la situation dans des dûˋlais trû´s brefs.
Exemplesô :
- Spamdexingô : parvenir û tromper l'algorithme du moteur de recherche pour que le site reûÏoive davantage d'audience qu'il le mûˋriteô ;
- Cloakingô : fournir au moteur de recherche une version diffûˋrente du site par rapport û ce que voient les visiteursô ;
- Link farmsô : construire un rûˋseau de sites qui s'ûˋchangent des liens, de maniû´re û augmenter leur quantitûˋ de backlinksô ;
- etc.
Je ne souhaite pas donner davantage de dûˋtails ici puisque je n'adhû´re pas û ces techniques.
I-E. Principes gûˋnûˋraux▲
Pour optimiser ses pages Web, il suffit d'ûˆtre le plus honnûˆte possible.
Voici quelques ûˋlûˋmentsô :
- construisez des pages au contenu consûˋquentô : ayez du volume sans pour autant faire dans la longueurô ;
- organisez votre contenuô : structure du site, arborescenceô ;
- rûˋdigez correctementô : orthographe, grammaire, etc.ô ;
- mettez en formeô : titre, gras, italique, etc.ô ;
- pensez û mettre une balise <h1></h1> dans chaque page, û renseigner la balise <title></title>ãÎ
Vous remarquez le point centralô : le contenu. Tout s'applique û mettre en valeur le contenu de votre page. Pourquoiô ? Simplement parce que c'est ce que le visiteur cherche dans le moteur de recherche. Il veut une rûˋponse û une question, donc du contenu. C'est û cela qu'il faut penser quand vous optimisezô : sûˋlectionnez les mots clefs que le visiteur devra pouvoir trouver dans vos pages et brodez û partir de cela. Vos liens doivent contenir un texte d'ancrage faisant rûˋfûˋrence û ces mots ou û des synonymesô ; les mots eux-mûˆmes doivent ûˆtre situûˋs û des endroits stratûˋgiques (titres, en dûˋbut de page, mis en forme, etc.)ãÎ