



V. Maintenance des donnĂ©es d’un index▲
Les données d’index Solr peuvent être mises à jour avec un document au format CSVUpdating a Solr Index with CSV ou XMLUpdating a Solr Index with XML. D’après le fichier solrconfig.xml d’exemple, les formats javabin et JSONUpdating a Solr Index with JSON sont aussi disponibles, mais la documentation à ce sujet est moins abondante et je n’ai pas vérifié moi-même. Quel que soit son format, le document doit être soumis à Solr via la méthode HTTP POST. Dans les paragraphes suivants, nous allons voir comment le document doit être structuré et de quelle manière nous pouvons l’envoyer à Solr.
Le format XML a ma préférence sur le format CSV, car il est plus facile à relire que ce dernier, surtout dans le cas des champs multivalués. Avec un document CSV, les choses se compliquent dès que le texte à indexer contient le caractère de séparation de champ ou un saut de ligne (ce qui est une situation plutôt courante).
V-A. Configuration nĂ©cessaire▲
Afin de pouvoir envoyer des mises à jour de l’index au noyau, il nous faut configurer le noyau avec le requestHandler que nous utiliserons :
<requestHandler name="/update" class="solr.XmlUpdateRequestHandler" />
<requestHandler name="/update/javabin" class="solr.BinaryUpdateRequestHandler" />
<requestHandler name="/update/csv" class="solr.CSVRequestHandler" startup="lazy" />
<requestHandler name="/update/json" class="solr.JsonUpdateRequestHandler" startup="lazy" />Dans la mesure où il est peu raisonnable de développer et de maintenir plusieurs manières de mettre un index à jour, vous n’aurez probablement besoin que d’un seul requestHandler « update ». Ainsi, vous pouvez déclarer uniquement le handler de base « /update » et choisir sa classe Java en fonction de vos besoins :
<requestHandler name="/update" class="solr.XmlUpdateRequestHandler" /><requestHandler name="/update" class="solr.BinaryUpdateRequestHandler" /><requestHandler name="/update" class="solr.CSVRequestHandler" startup="lazy" /><requestHandler name="/update" class="solr.JsonUpdateRequestHandler" startup="lazy" />V-B. Ajout et modification de donnĂ©es▲
Le document XML est construit de la manière suivante :
<add>
<doc>
<field name=""></field>
<field name=""></field>
<field name=""></field>
</doc>
<doc>
<field name=""></field>
<field name=""></field>
<field name=""></field>
</doc>
</add>Des exemples plus complets sont distribués avec Solr (6).
Chaque nœud <doc> correspond à un document de l’index. Il contient l’ensemble des champs définis dans le fichier schema.xml pour ce noyau.
Les champs définis avec l’attribut required="true" dans le schéma doivent obligatoirement figurer pour chaque nœud <doc>. Un même champ peut apparaître plusieurs fois dans le même nœud <doc> s’il s’agit d’un champ multivalué, c’est-à -dire défini avec l’attribut multivalued="true" dans le schéma. Les autres champs ne peuvent apparaître qu’une seule fois pour chaque nœud <doc>.
Comme nous l’avons vu dans le chapitre précédent, la contrainte d’unicité d’un index est le champ défini comme <uniqueKey> dans le schéma. Pour Solr, il n’y a pas de distinction entre les opérations « create » et « update » des documents : lorsque le requestHandler de mise à jour est appelé pour une certaine uniqueKey, Solr s’occupe de créer le document correspondant s’il n’existait pas encore, ou de le modifier s’il existait déjà .
Voici les attributs optionnels pour chaque nœud XML du document de mise à jour :
|
NĹ“ud |
Attribut |
Valeurs |
Description |
|---|---|---|---|
|
add |
overwrite |
true | false |
Remplacer les documents ayant la mĂŞme uniqueKey |
|
add |
commitWithin |
millisecondes |
Valider le document après ce délai |
|
doc |
boost |
float |
Augmenter la pertinence de ce document complet pour la recherche (si omitNorms="false" dans le schéma) |
|
field |
boost |
float |
Augmenter la pertinence de ce champ pour la recherche (si omitNorms="false" dans le schéma) |
Lors de la configuration des champs de l’index par l’intermédiaire du fichier schema.xml, les champs déclarés comme « dest » de <copyField/> ne doivent pas figurer dans les mises à jour. Par exemple, pour le schéma donné dans cet article, nous pouvons résumer la liste des champs par le tableau suivant :
|
Champ |
schema:copyField |
schema:field[required] |
Présence dans doc. de mà j |
|---|---|---|---|
|
uuid |
non défini |
oui |
oui, obligatoire |
|
productNameEnDisplay |
source |
non |
oui, facultatif |
|
productNameFrDisplay |
source |
non |
oui, facultatif |
|
productNameEnAutoComplete |
dest |
non |
non |
|
productNameFrAutoComplete |
dest |
non |
non |
|
productNameEnSearch |
dest |
non |
non |
|
productNameFrSearch |
dest |
non |
non |
|
manufacturerNameDisplay |
source |
non |
oui, facultatif |
|
manufacturerNameAutoComplete |
dest |
non |
non |
|
manufacturerNameEnSearch |
dest |
non |
non |
|
manufacturerNameFrSearch |
dest |
non |
non |
|
allEnSearch |
dest |
non |
non |
|
allFrSearch |
dest |
non |
non |
Cela pourrait donner le document XML suivant :
<add>
<doc>
<field name="uuid"></field>
<field name="productNameEnDisplay"></field>
<field name="productNameFrDisplay"></field>
<field name="manufacturerNameDisplay"></field>
</doc>
</add>Les champs suivants de l’index sont remplis par l’intermédiaire de copyField :
- productNameEnAutoComplete
- productNameFrAutoComplete
- productNameEnSearch
- productNameFrSearch
- manufacturerNameAutoComplete
- manufacturerNameEnSearch
- manufacturerNameFrSearch
- allEnSearch
- allFrSearch
V-C. Suppression de donnĂ©es▲
La suppression de documents d’un index se fait au moyen d’un document delete contenant une combinaison de nœuds id et query :
<delete>
<query>*:*</query>
</delete><delete>
<id>05991</id>
</delete><delete>
<id>05991</id>
<id>06000</id>
<query>office:Bridgewater</query>
<query>office:Osaka</query>
</delete>La syntaxe du nœud query pour la suppression de données est la même que pour la recherche avec un searchHandler. Nous aborderons cela plus loin dans l’article.
Le nom du nœud id est figé, il ne peut pas prendre le nom d’un champ du schéma. Solr s’attend à trouver le contenu de ce nœud dans le champ défini comme uniqueKey dans le schéma. Pour le schéma présenté dans cet article, les deux requêtes suivantes sont équivalentes :
<delete>
<id>aaaa</id>
</delete><delete>
<query>uuid:aaaa</query>
</delete>V-D. Validation de mises Ă jour▲
La validation des mises à jour se fait par les commandes suivantes :
<commit/><optimize/>Voici les attributs optionnels du document de mise à jour :
|
NĹ“ud |
Attribut |
Valeurs |
Description |
|---|---|---|---|
|
commit et optimize |
waitFlush |
true | false |
Bloquer jusqu’à ce que les modifications de l’index soient écrites sur le disque |
|
commit et optimize |
waitSearcher |
true | false |
Bloquer jusqu’à ce qu’un nouveau chercheur soit ouvert et enregistré comme le chercheur principal, rendant ainsi les modifications visibles |
|
commit |
expungeDeletes |
true | false |
Ignorer les suppressions |
|
optimize |
maxSegments |
int |
Optimiser jusqu’à ce nombre de segments individuels |
V-E. Annulation de mises Ă jour▲
La commande rollback permet d’annuler toutes les commandes add et delete depuis la dernière commande commit ou optimize :
<rollback/>V-F. Soumettre le document de maintenance▲
L’envoi d’un document de maintenance à Solr se fait via la méthode HTTP POST au requestHandler « update » de notre noyau, par exemple :
http://localhost:8080/solr/CORENAME/update
V-G. Exemple▲
Préparons un XML à envoyer :
<add>
<doc>
<field name="uuid">f2446de21f011a769ec62b4c4ecb96d2</field>
<field name="productNameEnDisplay">Solr, the enterprise search server</field>
<field name="productNameFrDisplay">Solr, le serveur de recherche pour entreprises</field>
<field name="manufacturerNameDisplay">Apache Software Foundation</field>
</doc>
</add>Envoyons ce XML à l’aide de cURL :
curl http://localhost:8080/solr/CORENAME/update -H "Content-Type: text/xml" --data-binary "<delete><query>*:*</query></delete>"
curl http://localhost:8080/solr/CORENAME/update -H "Content-Type: text/xml" --data-binary "INSERER_ICI_TOUT_LE_XML"
curl http://localhost:8080/solr/CORENAME/update -H "Content-Type: text/xml" --data-binary "<optimize waitSearcher='false'/>"cURL est le logiciel habituellement utilisé pour cette démonstration, mais vous n’êtes pas obligés d’y avoir recours. Vous pouvez utiliser le programme de votre choix, voire développer un petit script ou programme avec le langage de votre préférence.
Le code suivant est un exemple de script PHP pouvant fonctionner avec une installation PHP par défaut (ni le programme cURL ni l’extension php_curl ne sont nécessaires) :
#!/usr/bin/php5
<?php
if(PHP_SAPI != 'cli')
{
die('error: not sent via CLI'.PHP_EOL);
}
if($argc != 4 or !in_array($argv[2], array('file', 'string')))
{
die('usage is: '.basename(__FILE__).' CORENAME "file"|"string" FILENAME|CONTENTS'.PHP_EOL);
}
list(, $core_name, $content_type, $content) = $argv;
$url = sprintf('http://localhost:8080/solr/%s/update', $core_name);
$data = $content_type == 'string' ? $content : file_get_contents($content);
$params = array
(
'http' => array (
'method' => 'POST'
, 'header' => 'Content-Type: text/xml'
, 'content' => $data
, 'timeout' => 5
)
);
$context = stream_context_create($params);
$result = file_get_contents($url, FALSE, $context);
var_dump($result);
echo 'done'.PHP_EOL;./send.php produits string "<delete><query>*:*</query></delete>"
./send.php produits file add1.xml
./send.php produits string "<optimize waitSearcher='true'/>"php.exe send.php produits string "<delete><query>*:*</query></delete>"
php.exe send.php produits file add1.xml
php.exe send.php produits string "<optimize waitSearcher='true'/>"Pour vérifier que les modifications ont bien été effectuées, vous pouvez charger la page suivante :
http://localhost:8080/solr/admin/cores?core=CORENAME&action=status

Afin de vérifier plus précisément ce qui a été fait par Solr, notamment que les directives copyField ont réussi, voici une requête simple sur l’index :
http://localhost:8080/solr/produits/select?q=uuid:f2446de21f011a769ec62b4c4ecb96d2
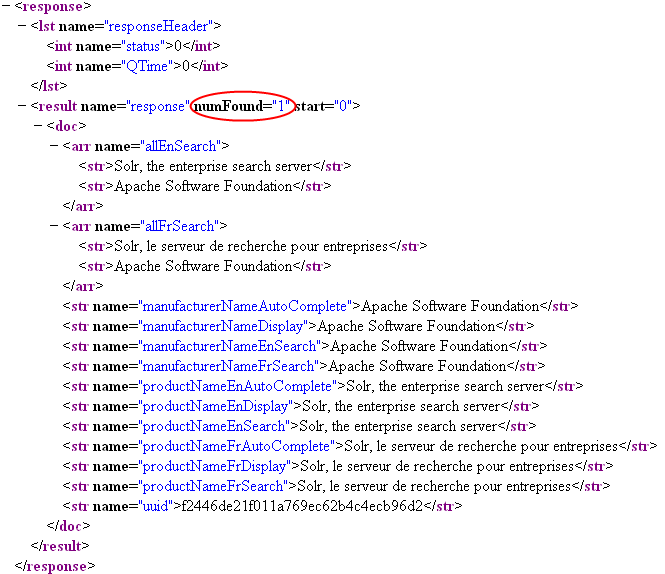
Rappelons les champs envoyés à Solr :
- uuid
- productNameEnDisplay
- productNameFrDisplay
- manufacturerNameDisplay
La capture d’écran ci-dessus montre que Solr a bel et bien rempli tous les champs de l’index d’après les règles copyField. Comme prévu, certains champs de l’index contiennent plusieurs valeurs.