



IV. La structure des documents du noyau : schema.xml▲
Cette page sert de référence au reste de l'article. Si vous n'avez pas la patience de la lire de bout en bout à la première lecture, ce qui serait tout à fait normal, n'hésitez pas à passer à la suite pour le moment. Vous pourrez revenir sur cette page lorsque vous aurez besoin de configurer votre schéma ou votre API.
À tout moment, vous pouvez regarder le fichier example/solr/conf/schema.xmlSchéma d'exemple de l'archive téléchargée. Ce fichier est très complet et il contient de nombreux commentaires pour vous aider dans vos prises de décisions.
- un nœud types
- un nœud fields
- un champ uniqueKey
- un champ defaultSearchField
- un champ solrQueryParser
- un ou plusieurs champs copyField
IV-A-1. Les types de donnĂ©es du document : /schema/types▲
IV-A-1-1. Introduction▲
Chaque fieldType est décrit au moins par deux attributs name et class. Le premier permet de faire référence à ce type dans le reste du fichier XML ; l'autre décrit la classe Java utilisée pour construire le type en mémoire.
Les champs de notre document devront être définis soit avec un type simple, soit avec un type complexe. Les types dits "simples" sont pour des données brutes, c'est-à -dire des chaînes sans signification sémantique, des valeurs numériques ou des dates. Les types dits "complexes" sont prévus pour décomposer la valeur et pour l'analyser de manière très précise. Nous allons commencer par les types simples, que tout développeur a rencontrés maintes fois dans ses projets, puis nous verrons les types complexes, qui constituent la majorité de la valeur ajoutée de Solr.
IV-A-1-2. Les attributs disponibles pour chaque type de donnĂ©es▲
La plupart des attributs suivants sont disponibles à la fois dans les définitions fieldType et field. L'expérience vous dira à quel endroit chaque attribut est le plus utile.
| Nom | Description | Valeurs | Obligatoire | Valeur par défaut |
|---|---|---|---|---|
| name | Nom du type | chaîne | oui | n/a |
| class | Nom de la classe Java | chaîne | oui | n/a |
| indexed | Mettre Ă vrai si ce type doit ĂŞtre disponible pour la recherche ou le tri | false|true | non | false |
| stored | Mettre à vrai si ce type peut être renvoyé par un requestHandler | false|true | non | false |
| compressed | Mettre à vrai si le type doit être compressé (gzip) ; utile uniquement pour StrField et TextField | false|true | non | false |
| compressThreshold | Longueur minimale de la valeur pour activer la compression ; utile uniquement si compressed est activé | entier | non | 0 |
| multiValued | Mettre Ă vrai si ce type peut contenir plusieurs valeurs par document | false|true | non | false |
| precisionStep | Une valeur faible améliore le temps de recherche
Une valeur élevée améliore le temps d'indexation et le volume de stockage |
entier | non | Selon classe Java |
| omitNorms | Mettre Ă vrai si vous avez besoin de pouvoir trier sur ce type | false|true | non | false |
| omitTermFreqAndPositions | Mettre à vrai si vous n'avez besoin ni de la fréquence des termes ni de leur position ni de leur pondération (payload) | false|true | non | false |
| positionIncrementGap | Mettre à 100 pour les types de texte multivalué, ou bien à 0 pour le reste | entier | non | 0 |
| termVectors | Mettre Ă vrai si vous utilisez HighlightComponent, MoreLikeThisComponent ou TermVectorComponent Inutile si le champ n'est pas de classe TextField |
false|true | non | false |
| termPositions | Mettre Ă vrai si vous utilisez termVectors | false|true | non | false |
| termOffsets | Mettre Ă vrai si vous utilisez termVectors | false|true | non | false |
| sortMissingFirst | Pousser les documents n'ayant pas de valeur vers le début de la liste
Utile uniquement pour les types dont la représentation interne de la valeur est une chaîne (StrField, BoolField, DateField et les Sortable*) |
false|true | non | false |
| sortMissingLast | Pousser les documents n'ayant pas de valeur vers la fin de la liste
Utile uniquement pour les types dont la représentation interne de la valeur est une chaîne (StrField, BoolField, DateField et les Sortable*) |
false|true | non | false |
| default | Â | Selon le fieldType du champ | non | vide |
Vous trouverez ci-dessous une liste des attributs recommandés ou obligatoires pour chaque cas d'utilisation (1). Une étoile bleue (*) marque les valeurs recommandées mais non obligatoires.
| Cas d'utilisation \ Attribut | indexed | stored | multiValued | omitNorms | termVectors | termPositions | termOffsets |
|---|---|---|---|---|---|---|---|
| Recherche dans le champ | true | Â | Â | Â | Â | Â | Â |
| Récupérer le contenu du champ |  | true |  |  |  |  |  |
| Utiliser comme uniqueKey | true | Â | false | Â | Â | Â | Â |
| Trier sur le champ | true | Â | false | true * | Â | Â | Â |
| Utiliser la pondération de champ (field boost) |  |  |  | false |  |  |  |
| La pondération de document (document boost) affecte la recherche sur ce champ |  |  |  | false |  |  |  |
| Récupérer la surbrillance (HighlightComponent) | true * | true |  |  | true * | true * | true * |
| Récupérer les facettes (FacetComponent) | true |  |  |  |  |  |  |
| Ajouter des valeurs multiples tout en conservant l'ordre | Â | Â | true | Â | Â | Â | Â |
| La longueur de la valeur affecte le score du document | Â | Â | Â | false | Â | Â | Â |
| Récupérer les résultats similaires (MoreLikeThisComponent) |  | true * |  |  | true * |  |  |
| TermVectorComponent : Fréquence des termes |  |  |  |  | true |  |  |
| TermVectorComponent : Fréquence du document |  |  |  |  | true |  |  |
| TermVectorComponent : tf * idf | Â | Â | Â | Â | true | Â | Â |
| TermVectorComponent : Position des termes | Â | Â | Â | Â | true | true | true |
| TermVectorComponent : DĂ©calage des termes | Â | Â | Â | Â | true | true | true |
Certains cas d'utilisation sont incompatibles. Il est par exemple impossible de trier les résultats sur un champ pouvant avoir plusieurs valeurs, dans la mesure où son attribut multiValued devrait avoir à la fois les valeurs true et false.
IV-A-1-3. Les types simples▲
| Classe | Nom | Optimisations | Description |
|---|---|---|---|
| solr.StrField | string | non indexé | Type chaîne générique |
| solr.BoolField | boolean |  | Type booléen, peut prendre pour valeurs "true", "false", "0" ou "1" |
| solr.BinaryField | binary |  | Type de données dont les valeurs doivent être encodées en base64 |
| solr.TrieIntField | tint | recherche, tri | Type numérique "int" |
| solr.TrieFloatField | tfloat | recherche, tri | Type numérique "float" |
| solr.TrieLongField | tlong | recherche, tri | Type numérique "long" |
| solr.TrieDoubleField | tdouble | recherche, tri | Type numérique "double" |
| solr.TrieDateField | tdate | recherche, tri | Type date selon le format ISO 8601 (cf. la RFC 3339Date and Time on the Internet: Timestamps ou le W3CNote: Date and Time Formats) avec pour zone obligatoire "Z" (UTC), par exemple : "1995-12-31T23:59:59Z" |
| solr.RandomSortField | random |  | Type pour faciliter les tris aléatoires |
Je ne présente ci-dessus que les types utiles avec la version de Solr choisie. En effet, les versions antérieures de schema.xml avaient plusieurs versions de chaque type de base. Ces types continuent d'exister afin de permettre la compatibilité avec d'anciens schémas mais, pour un schéma nouvellement défini, ils sont obsolètes.
À titre d'exemple, voici les trois versions du type entier (int). Remarquons l'utilisation d'un préfixe selon le principe de la notation hongroiseArticle Wikipédia sur la notation hongroise (cf. notation hongroise Apps) afin de décrire le contexte de chaque type : pint, sint, tint.
| Classe | Nom | Surnom | Description |
|---|---|---|---|
| solr.IntField | pint | plain int | aucune optimisation, lent pour les recherches et les tris |
| solr.SortableIntField | sint | sortable int | représentation du nombre sous forme de texte, ce qui permet le tri mais n'est pas optimisé pour les requêtes |
| solr.TrieIntField | tint | trie int | le nombre est indexé et manipulé avant d'être enregistré dans l'index, ce qui permet d'appliquer des optimisations pour le tri et la recherche tout en améliorant les performances des requêtes |
Le seul avantage des types "plain" sur les autres est un gain de place pour l'index, mais ce n'est habituellement pas l'argument qui oriente le projet vers Solr ; de plus, dans la mesure où ces valeurs sont stockées telles quelles par Solr, elles ne sont pas utilisables pour des tris naturels.
Les types "sortable" sont meilleurs que les types "plain" car ils représentent les valeurs sous forme d'une chaîne, manipulée de manière à permettre les tris naturels.
Enfin, les types "trie" sont mieux optimisés que les types "sortable" pour les requêtes d'intervalles car Solr passe par des analyses et des filtres pour indexer ces valeurs (plutôt que de les représenter sous forme de texte).
Dans la mesure où nous n'avons pas besoin de conserver la compatibilité avec un ancien index, nous ne choisirons pas les types "plain" pour lesquels nous avons une alternative : un type "sortable" chaque fois que nous aurons besoin de sortMissingLast ou sortMissingFirst, ou "trie" le reste du temps. Nous allons donc ajouter les déclarations suivantes dans le nœud <types></types> de notre fichier schema.xml (ces déclarations ont peu de chances de différer d'un noyau à l'autre) :
<!-- Types de base -->
<fieldType name="string" class="solr.StrField"
sortMissingLast="true" omitNorms="true"/>
<fieldType name="boolean" class="solr.BoolField"
sortMissingLast="true" omitNorms="true"/>
<fieldtype name="binary" class="solr.BinaryField"/>
<fieldType name="random" class="solr.RandomSortField"
indexed="true" />
<!-- Types numériques permettant d'utiliser sortMissingLast ou sortMissingFirst -->
<fieldType name="sint" class="solr.SortableIntField"
sortMissingLast="true" omitNorms="true"/>
<fieldType name="sfloat" class="solr.SortableFloatField"
sortMissingLast="true" omitNorms="true"/>
<fieldType name="slong" class="solr.SortableLongField"
sortMissingLast="true" omitNorms="true"/>
<fieldType name="sdouble" class="solr.SortableDoubleField"
sortMissingLast="true" omitNorms="true"/>
<!-- Types numériques optimisés pour les requêtes par intervalles -->
<fieldType name="tint" class="solr.TrieIntField"
precisionStep="8" omitNorms="true" positionIncrementGap="0"/>
<fieldType name="tfloat" class="solr.TrieFloatField"
precisionStep="8" omitNorms="true" positionIncrementGap="0"/>
<fieldType name="tlong" class="solr.TrieLongField"
precisionStep="8" omitNorms="true" positionIncrementGap="0"/>
<fieldType name="tdouble" class="solr.TrieDoubleField"
precisionStep="8" omitNorms="true" positionIncrementGap="0"/>
<fieldType name="tdate" class="solr.TrieDateField"
precisionStep="6" omitNorms="true" positionIncrementGap="0"/>Les champs de type StrField ne sont pas analysés par Solr, ils sont stockés tels quels. Aucune optimisation n'est apportée sur ces valeurs pour le tri, la recherche ou les requêtes par intervalles. Ainsi, il ne faut pas utiliser ce type de données pour les champs sur lesquels on souhaite effectuer des tris ou des recherches.
Les noms de classes commençant par "solr" sont directement liés aux classes Java du paquetage org.apache.solr.schema (même si le fichier schema.xml par défaut indique org.apache.solr.analysis : il s'agit sans doute d'une erreur). Par exemple, un type solr.StrField instancie des objets de la classe Java org.apache.solr.schema.StrFieldClass StrField. N'ayez crainte, il n'est pas nécessaire de connaître l'API Java pour configurer un noyau Solr performant. Je ne donne ce lien qu'à titre indicatif.
Il ne faut pas confondre les types de données que nous manipulons en tant qu'utilisateurs de la webapp (StrField, BoolField etc.) et la "représentation interne" que j'évoque par moments.
IV-A-1-4. Les types complexes▲
IV-A-1-c-i. Description d'un type complexe▲
Les types complexes ne sont ni présents ni configurés par défaut dans Solr. Bien que les exemples présentent parfois des types complexes génériques, leur utilité est très limitée car ils ne sont pas adaptés à votre application ou à votre noyau. C'est à vous, en tant que créateur du noyau, de définir les besoins de votre application et de configurer les types Solr permettant d'y répondre. Ce sont ces types configurables qui surpassent de très loin les fonctionnalités offertes par les opérateurs LIKE et REGEXP du langage SQL ainsi que, dans une moindre mesure, la plupart des autres moteurs full-text. C'est pour les utiliser que vous vous êtes tourné(e) vers Solr.
Un type complexe est configuré à partir du type solr.TextField auquel on ajoute un ou deux analyseurs (<analyzer></analyzer>), eux-mêmes composés d'une suite de <tokenizer/> et de <filter/>.
Comme nous l'avons évoqué plus haut, les types complexes sont la raison principale qui oriente un projet vers l'intégration de Solr. En effet, ce sont des types dont les données seront analysées, manipulées et comparées à un niveau dont la profondeur est largement supérieure à ce que SQL peut faire avec des opérateurs comme LIKE et REGEXP, voire même souvent avec les modules Full-Text des moteurs SGBD, sans pour autant perdre en efficacité (temps de réponse). Voici un exemple permettant aux requêtes "wifi" et "wi fi" de trouver les documents contenant le mot "Wi-Fi", sans aucun code de manipulation de la requête dans l'application Web :
<fieldType name="text" class="solr.TextField" positionIncrementGap="100">
<analyzer type="index">
<tokenizer class="solr.WhitespaceTokenizerFactory"/>
<filter class="solr.WordDelimiterFilterFactory"
generateWordParts="1" generateNumberParts="1"
catenateWords="1" catenateNumbers="1" catenateAll="0"
splitOnCaseChange="1"/>
<filter class="solr.LowerCaseFilterFactory"/>
</analyzer>
<analyzer type="query">
<tokenizer class="solr.WhitespaceTokenizerFactory"/>
<filter class="solr.WordDelimiterFilterFactory"
generateWordParts="1" generateNumberParts="1"
catenateWords="0" catenateNumbers="0" catenateAll="0"
splitOnCaseChange="1"/>
<filter class="solr.LowerCaseFilterFactory"/>
</analyzer>
</fieldType>Nous pouvons voir dans cet exemple que Solr peut se comporter différemment selon qu'il rencontre le même mot dans un document mis à l'index ou dans une requête utilisateur. Nous pourrons voir plus en détail comment Solr manipule le texte lorsque notre premier noyau sera totalement configuré, mais voici un avant-goût :
- La chaîne est décomposée en sous chaînes à l'aide des espaces ;
- Chaque sous chaîne est à son tour décomposée à l'aide des séparateurs de mots, des nombres et du changement de casse ("Wi-Fi" devient à la fois "WiFi" et "Wi" + "Fi") ;
- Chaque élément est enfin mis en minuscules ("wifi", "wi" et "fi").
- La chaîne est décomposée en sous chaînes à l'aide des espaces ;
- Chaque sous chaîne est à son tour décomposée à l'aide des séparateurs de mots, des nombres et du changement de casse ("wi fi" devient "wi" + "fi") ;
- Chaque élément est enfin mis en minuscules ("wi" et "fi").
Revenons à la composition de fieldType pour un type complexe. Un nœud fieldType peut contenir jusqu'à deux nœuds analyzer. Ces derniers peuvent contenir un nombre quelconque de nœuds charFilter (choisis parmi les CharFilterFactories) suivis d'un nœud tokenizer (unique, obligatoire et choisi parmi les TokenizerFactories) et enfin d'un nombre quelconque de nœuds filter (choisis parmi les TokenFilterFactories).
- CharFilterFactories (0,*)
- TokenizerFactories (1, 1)
- TokenFilterFactories (0, *)
Si un nœud fieldType n'a aucun nœud analyzer, c'est un type simple. S'il a exactement deux nœuds analyzer, alors l'un d'eux doit être de type "index" et l'autre de type "query", comme le montre l'exemple précédent. En revanche, s'il n'a qu'un seul nœud analyzer, ce dernier ne doit pas porter d'attribut type car il s'applique aux deux types d'analyseurs pour ce fieldType (les requêtes et l'indexation se feront selon les mêmes règles).
Les tableaux qui suivent ne prétendent pas donner une liste exhaustive des classes disponibles. Ce sont les plus utilisées, mais Solr en propose davantagePackage org.apache.solr.analysis et vous avez toujours la possibilité d'écrire vos propres pluginsSolr Plugins.
IV-A-1-c-ii. Filtrer les caractères : les CharFilterFactories▲
Si vous en avez besoin, la documentation officielle de cette section est sur le wiki de SolrSolr analyzers, tokenizers, and token filters: CharFilterFactories et la liste complète des classes fournies par Solr est dans la documentation JavaInterface CharFilterFactory.
Toute classe ne figurant pas dans src/java/org/apache/solr/analysis/*CharFilterFactory.java de l'archive téléchargée, n'est pas disponible dans votre version de Solr.
| Classe | Effet | Paramètres |
|---|---|---|
| solr.MappingCharFilterFactory | Remplacer des caractères d'après les correspondances décrites dans un fichier texte | mapping="fichier.ext" |
| solr.HTMLStripCharFilterFactory | Supprimer les balises HTML | Â |
Si vous souhaitez utiliser une classe solr.MappingCharFilterFactory, alors vous devrez créer un fichier texte dans le dossier "conf" du noyau. Cette technique a souvent été utilisée pour remplacer les lettres accentuées par leur équivalent non accentué grâce au fichier mapping-ISOLatin1Accent.txtConvertir les caractères accentués en équivalent ASCII-127 (2). Cependant, Solr propose une meilleure solution : le filtre solr.ASCIIFoldingFilterFactory (cf. plus bas).
Afin d'être parfaitement clair : <charFilter class="solr.MappingCharFilterFactory" n'est pas la bonne solution au problème des accents. La bonne solution est <filter class="solr.ASCIIFoldingFilterFactory", que nous verrons dans le paragraphe sur les TokenFilterFactories.
Si vous avez besoin de la classe solr.MappingCharFilterFactory malgré tout, alors voici la syntaxe du fichier texte :
# Syntaxe (la source ne peut pas ĂŞtre vide, la cible peut ĂŞtre vide) :
# "source" => "cible"
# Exemples :
# "Ă€" => "A"
# "\u00C0" => "A"
# "\u00C0" => "\u0041"
# "Ăź" => "ss"
# "\t" => " "
# "\n" => ""Ainsi, vous pouvez remplacer une chaîne "source" non vide par une chaîne "cible", vide ou non. Puisque tout est encodé en UTF-8 dans Solr, vous devez préciser les valeurs UTF-8 des caractères sous leur forme hexadécimale : c'est l'une des raisons qui rendent l'alternative solr.ASCIIFoldingFilterFactory attrayante.
<charFilter class="solr.HTMLStripCharFilterFactory"/>Il existe aussi les classes solr.BaseCharFilterFactory et solr.PatternReplaceCharFilterFactory mais, n'ayant pas trouvé leur liste de paramètres, je ne suis pas parvenu à les faire fonctionner.
IV-A-1-c-iii. DĂ©composer la chaĂ®ne : les TokenizerFactories▲
Si vous en avez besoin, la documentation officielle de cette section est sur le wiki de SolrSolr analyzers, tokenizers, and token filters: TokenizerFactories et la liste complète des classes fournies par Solr est dans la documentation JavaInterface TokenizerFactory.
Toute classe ne figurant pas dans src/java/org/apache/solr/analysis/*TokenizerFactory.java de l'archive téléchargée, n'est pas disponible dans votre version de Solr.
| Classe | Effet | Paramètres |
|---|---|---|
| solr.LetterTokenizerFactory | Découpe la chaîne d'après les lettres non contiguës |  |
| solr.WhitespaceTokenizerFactory | Découpe la chaîne d'après les espaces |  |
| solr.LowerCaseTokenizerFactory | Découpe la chaîne d'après les espaces puis passe les termes en minuscules |  |
| solr.StandardTokenizerFactory | Découpe la chaîne de manière intelligente et naturelle, tout en gardant une trace du types des termes isolés (acronymes, apostrophes, etc.) afin de permettre aux filter d'effectuer des traitements spécialisés
À utiliser avec un StandardFilter (cf. plus loin) Sauf si vous avez besoin d'un filter incompatible ou si vous l'appliquez à une langue trop éloignée de l'anglais, c'est généralement le meilleur choix pour le tokenizer |
 |
| solr.HTMLStripWhitespaceTokenizerFactory | Supprime le HTML puis se comporte comme un WhitespaceTokenizer | Â |
| solr.HTMLStripStandardTokenizerFactory | Supprime le HTML puis se comporte comme un StandardTokenizer | Â |
| solr.PatternTokenizerFactory | Découpe la chaîne selon une expression rationnelleInitiation aux expressions régulières en PHP | pattern="regexp" |
À mon humble avis, certaines de ces classes font du travail qui ne leur incombe pas. Par exemple, les classes HTMLStrip*Tokenizer font double emploi avec HTMLStripCharFilter, ainsi que LowerCaseTokenizer avec LowerCaseFilter (que nous verrons plus loin). Ma recommandation est de choisir un tokenizer pour segmenter la chaîne et de laisser les transformations aux charFilter et aux filter.
<tokenizer class="solr.StandardTokenizerFactory"/>Nous avons dit qu'un nœud analyzer doit contenir un nœud tokenizer, ni plus ni moins, or il peut arriver que vous ayez besoin d'un analyzer sans qu'aucun tokenizer ne modifie la chaîne. Dans ce cas, utilisez la classe "solr.KeywordTokenizerFactory", elle n'a aucun effet et elle rendra valide votre analyzer.
IV-A-1-c-iv. Manipuler les termes : les TokenFilterFactories▲
Si vous en avez besoin, la documentation officielle de cette section est sur le wiki de SolrSolr analyzers, tokenizers, and token filters: TokenFilterFactories et la liste complète des classes fournies par Solr est dans la documentation JavaInterface TokenFilterFactory.
Toute classe ne figurant pas dans src/java/org/apache/solr/analysis/*TokenFilterFactory.java de l'archive téléchargée, n'est pas disponible dans votre version de Solr.
| Classe | Effet | Paramètres |
|---|---|---|
| solr.StandardFilterFactory | Si vous avez utilisé solr.StandardTokenizer ou un équivalent, ce filtre permet de supprimer les points des acronymes et les 's de la fin des mots (qui, en anglais, correspond à un possessif ou à un pluriel) |  |
| solr.LowerCaseFilterFactory | Passe les termes en minuscules | Â |
| solr.TrimFilterFactory | Supprime les espaces en début et fin des termes |  |
| solr.StopFilterFactory | Supprime les termes les plus communs de la langue anglaise
Si le paramètre words est précisé, alors le fichier est utilisé à la place des mots pré configurés |
words="stopwords_en.txtMots communs de la langue anglaise"(3) words="stopwords_fr.txtMots communs de la langue française"(4) ignoreCase="false|true" |
| solr.CommonGramsFilterFactory | Combine les "mots communs" en termes
Par exemple, les termes "cet" et "été" font partie des mots communs de la langue française et, pris individuellement, solr.StopFilterFactory permet de les exclure de la recherche ; cependant, la chaîne "cet été" est une recherche légitime : le filtre solr.CommonGramsFilterFactory créé le terme combiné "cet_été" afin de le rendre disponible à la recherche On configure habituellement ce filtre avec la même liste de termes que pour solr.StopFilterFactory |
words="stopwords_en.txt" words="stopwords_fr.txt" ignoreCase="false|true" |
| solr.EdgeNGramFilterFactory | Créé une liste de termes à partir de la lettre numéro minGramSize jusqu'à maxGramSize de chaque terme, par exemple pour minGramSize="2" et side="front" :
Nigerian => "ni", "nig", "nige", "niger", "nigeri", "nigeria", "nigeria", "nigerian" |
minGramSize="" maxGramSize="" side="back|front" |
| solr.KeepWordFilterFactory | L'inverse de solr.StopWordsFilterFactory, mais les paramètres et le format de fichier sont identiques | words="keepwords_en.txt" words="keepwords_fr.txt" ignoreCase="false|true" |
| solr.LengthFilterFactory | Supprime les termes dont la taille n'est pas comprise entre min et max | min="" max="" |
| solr.WordDelimiterFilterFactory | Découpe les termes en sous termes suivant certaines règles : contiguïté des lettres, changement de casse, changement lettre-chiffre dans un terme et supprime le "s" à la fin des termes
Les paramètres peuvent être combinés de n'importe quelle manière, cela génère des termes supplémentaires sans créer de conflit Ce filtre illustre l'intérêt d'avoir un analyseur différent pour l'indexation et pour les requêtes Attention, les tokenizers qui opèrent trop de modifications sur la chaîne limitent le champ d'action de ce filtre |
splitOnCaseChange="0|1" splitOnNumerics="0|1" stemEnglishPossessive="0|1" generateWordParts="0|1" generateNumberParts="0|1" catenateWords="0|1" catenateNumbers="0|1" catenateAll="0|1" preserveOriginal="0|1" types="wdftypes_en.txtExemple de types spécifiques pour WordDelimiterFilterFactory"(5) |
| solr.SynonymFilterFactory | Gestion des synonymes (mots simples ou mots composés)
Le format du ficher de synonymes est détaillé après ce tableau |
synonyms="synonyms_fr.txt" ignoreCase="false|true" expand="false|true" |
| solr.RemoveDuplicatesTokenFilterFactory | Supprime les doublons successifs
Ce filtre est plus efficace s'il est utilisé après tous les filtres pouvant générer de nouveaux termes |
 |
| solr.ISOLatin1AccentFilterFactory | Deprecated : cf. solr.ASCIIFoldingFilterFactory | Â |
| solr.ASCIIFoldingFilterFactory | Convertir les caractères accentués en équivalent "ASCII 127" lorsque c'est possible ; plus d'informations dans la documentationDocumentation Java de la classe ASCIIFoldingFilter Ce filtre est à préférer aux autres méthodes permettant d'enlever les accents |
 |
| solr.ShingleFilterFactory | Un shingle est une combinaison de termes formant un nouveau terme | maxShingleSize="2" minShingleSize="2" outputUnigrams="false|true" tokenSeparator=" " |
| solr.PositionFilterFactory | Permet d'optimiser certains cas particuliers en manipulant la position des termes dans le flux
Ce filtre est conseillé pour un analyseur de type="query" mais pas pour type="index" |
positionIncrement="0" |
| solr.ReversedWildcardFilterFactory | Permet d'optimiser les recherches préfixées ou ayant une wildcard (* ou ?) vers le début de la chaîne
Le paramètre withOriginal permet de conserver l'ordre original en plus de l'ordre inversé Le paramètre maxPosAsterisk définit la position maximale de l'astérisque pour déclencher le filtre Le paramètre maxPosQuestion définit la position maximale du point d'interrogation pour déclencher le filtre Le paramètre maxFractionAsterisk déclenche le filtre si la position de l'astérisque est inférieure à cette fraction du terme Le paramètre minTrailing définit le nombre minimum de caractères dans un terme (après la dernière wildcard) pour déclencher le filtre ; plus efficace si > 1 Ce filtre est conseillé pour un analyseur de type="index" mais pas pour type="query" |
withOriginal="false|true" maxPosAsterisk="3" maxPosQuestion="2" maxFractionAsterisk="0.33" minTrailing="2" |
| solr.PhoneticFilterFactory | Créé une représentation codée de la prononciation phonétique des termes
Le paramètre maxCodeLength n'est disponible que pour les encodages Metaphone et DoubleMetaphone Le paramètre inject détermine si les jetons originaux sont remplacés ou ajoutés au flux L'implémentation DoubleMetaphone de ce filtre ne permet pas d'obtenir l'alternative prévue par l'algorithme Double Metaphone original : pour cela, il faut utiliser solr.DoubleMetaphoneFilterFactory |
encoder="MetaphoneDocumentation Java pour la classe Metaphone"
encoder="DoubleMetaphoneDocumentaton Java pour la classe DoubleMetaphone" encoder="SoundexDocumentation Java pour la classe Soundex" encoder="RefinedSoundexDocumentation Java pour la classe RefinedSoundex" inject="false|true" maxCodeLength="" |
| solr.DoubleMetaphoneFilterFactory | Créé une représentation codée de la prononciation phonétique (Double Metaphone) des termes | inject="false|true"
maxCodeLength="" |
| solr.SnowballPorterFilterFactory | Racinisation (cf. l'introduction de cet article pour une définition) optimisée pour différentes langues
La liste complète est disponible sur le wiki de SolrLanguage analysis in Solr: SnowballPorterFilterFactory L'algorithme Snowball suppose que le texte est en minuscules |
language="French" language="German2" language="Spanish" ... |
Comme vous pouvez vous en douter, la plupart de ces filtres sont prévus pour la langue anglaise. Il vous incombe de trouver la version localisée des fichiers dont vous avez besoin, car Solr ne les fournit pas tous.
Le fichier utilisé par solr.SynonymFilterFactory suit le format suivant :
# Les lignes vides et les lignes commençant par dièse sont des commentaires
# Les séquences équivalentes de termes sont séparées par des virgules
# Les règles explicites prennent chaque séquence de termes du côté gauche de "=>"
# et les remplacent par chacune des alternatives du côté droit
# Ces types de règles ignorent le paramètre "expand" du schéma
# Exemples :
i-pod, i pod => ipod
sea biscuit, sea biscit => seabiscuit
# Les règles implicites ne prennent pas de "=>"
# En ce cas, le comportement est défini par le paramètre "expand" du schéma
# Cela permet d'utiliser le même fichier de synonymes pour différentes stratégies
# Exemples :
ipod, i-pod, i pod
foozball, foosball
universe, cosmos
# Si "expand" est à VRAI, alors la règle "ipod, i-pod, i pod" est équivalente à :
ipod, i-pod, i pod => ipod, i-pod, i pod
# Si "expand" est à FAUX, alors la règle "ipod, i-pod, i pod" est équivalente à :
ipod, i-pod, i pod => ipod
# Les règles multiples sont combinées
# Exemple :
foo => foo bar
foo => baz
# Devient :
foo => foo bar, bazLa recommandation officielle pour la gestion des synonymes (mono ou multi termes) est de définir expand="true" lorsque ce filtre est appliqué à un analyseur type="index" mais pas pour un analyseur type="query". Pour plus d'informations à ce sujet, veuillez lire la page Wiki de Solr sur ce filtreAnalyzers, Tokenizers, and Token Filters: solr.SynonymFilterFactory.
<filter class="solr.SnowballPorterFilterFactory" language="French"/>
<filter class="solr.RemoveDuplicatesTokenFilterFactory"/>Prenez garde à l'ordre de déclaration des classes dans votre analyseur ainsi qu'aux dépendances et aux incompatibilités entre classes. Je n'expliquerai pas toutes les subtilités dans cet article, vous allez devoir expérimenter par vous-mêmes.
- Utiliser un StandardFilter sans StandardTokenizer ;
- Utiliser un WordDelimiterFilter avec un tokenizer qui modifie davantage la chaîne que ne le ferait un WhitespaceTokenizer ;
- Utiliser un CommonGramsFilter sans avoir de StopFilter.
IV-A-1-5. Exemple de dĂ©claration de types▲
Ne prenez l'exemple ci-dessous qu'Ă des fins d'Ă©tude, ne l'utilisez pas tel quel dans votre application finale.
- Affichage : le seul traitement effectué sur la chaîne est un nettoyage cosmétique, ce type est donc adapté pour toutes les langues ;
- Auto complétion : les seuls traitements effectués sur la chaîne sont un nettoyage cosmétique et une segmentation en "n-grams", ce type est donc adapté pour toutes les langues ;
- Recherche en anglais : optimisation (index + requĂŞtes) pour la recherche en langue anglaise ;
- Recherche en français : optimisation (index + requêtes) pour la recherche en langue française.
Cela se traduit par le nœud XML types suivant :
<!-- Type texte pour l'affichage : très peu de traitements -->
<fieldType name="rawText" class="solr.TextField">
<analyzer>
<charFilter class="solr.HTMLStripCharFilterFactory"/>
<tokenizer class="solr.KeywordTokenizerFactory"/>
</analyzer>
</fieldType>
<!-- Type texte pour l'auto complétion -->
<!-- Le filtre EdgeNGram n'est adapté qu'à l'analyzer "index" -->
<fieldType name="grammedText" class="solr.TextField" positionIncrementGap="100">
<analyzer type="index">
<charFilter class="solr.HTMLStripCharFilterFactory"/>
<tokenizer class="solr.WhitespaceTokenizerFactory"/>
<filter class="solr.ASCIIFoldingFilterFactory"/>
<filter class="solr.LowerCaseFilterFactory"/>
<filter class="solr.EdgeNGramFilterFactory" minGramSize="2" maxGramSize="10"/>
</analyzer>
<analyzer type="query">
<charFilter class="solr.HTMLStripCharFilterFactory"/>
<tokenizer class="solr.WhitespaceTokenizerFactory"/>
<filter class="solr.ASCIIFoldingFilterFactory"/>
<filter class="solr.LowerCaseFilterFactory"/>
</analyzer>
</fieldType>
<!-- Type texte pour la recherche, avec traitements spécifiques à l'anglais -->
<fieldType name="englishText" class="solr.TextField" positionIncrementGap="100">
<analyzer>
<charFilter class="solr.HTMLStripCharFilterFactory"/>
<tokenizer class="solr.StandardTokenizerFactory"/>
<filter class="solr.LowerCaseFilterFactory"/>
<filter class="solr.SnowballPorterFilterFactory" language="English"/>
</analyzer>
</fieldType>
<!-- Type texte pour la recherche, avec traitements spécifiques au français -->
<fieldType name="frenchText" class="solr.TextField" positionIncrementGap="100">
<analyzer>
<charFilter class="solr.HTMLStripCharFilterFactory"/>
<tokenizer class="solr.WhitespaceTokenizerFactory"/>
<filter class="solr.LowerCaseFilterFactory"/>
<filter class="solr.SnowballPorterFilterFactory" language="French"/>
</analyzer>
</fieldType>IV-A-2. Les champs du document : /schema/fields▲
IV-A-2-1. Introduction▲
Après avoir défini les types de champs nécessaires à votre noyau, vous pouvez passer à la définition des champs utilisant ces types de données. C'est ce que nous allons voir ici.
Cette partie dépend majoritairement des besoins de votre application. Nous allons voir quelques exemples mais c'est à vous de construire les champs de données adaptés à votre cas d'utilisation.
<field name="uuid" type="string"/>Il faut penser à créer un champ unique de type string pour chaque noyau. Pour ma part, j'utilise généralement un hash (sha1, md5 ou autre) de la clef primaire de ma table source (SQL) et j'appelle ce champ "uuid" (cela facilite les traitements avec certains plugins de Solr) :
<field name="uuid" type="string" stored="true" required="true"/>Solr permet de copier la valeur d'un champ vers d'autres champs (nous verrons à la fin de cette section comment nous y prendre). Cela permet de faciliter l'import de données vers Solr puisqu'un <doc> contient les informations extraites directement de la source de données (par exemple votre base de données) sans se soucier de combien de variantes de chaque valeur le noyau a besoin (à l'identique, en minuscules, sans espaces, sans HTML, phonétique, etc.). Ainsi, la plupart des champs de votre schéma seront sans doute définis en plusieurs déclinaisons sans que cela ne complique d'aucune manière le procédé d'import de données vers votre noyau.
Une stratégie courante est de définir plusieurs versions de chaque champ de données : une copie exacte de l'original (dans chaque langue) et une copie supplémentaire pour chaque cas d'utilisation.
Une autre stratégie courante, et de surcroît compatible avec la précédente, est de définir un champ permettant de rassembler toutes les valeurs "texte" du document afin de faciliter les recherches.
IV-A-2-2. Les attributs disponibles pour chaque champ de donnĂ©es▲
Comme nous l'avons dit précédemment, les attributs d'un nœud field sont les mêmes que pour un nœud fieldType. C'est dû au fait que la classe Java utilisée pour instancier l'objet field est la même que celle utilisée pour instancier l'objet fieldType ; elle en prend donc les propriétés et les méthodes. C'est pour cette raison qu'il est possible de définir une surcharge pour chacun des attributs au niveau du field par rapport aux valeurs définies pour les mêmes attributs au niveau du fieldType, qui peuvent elles-mêmes surcharger les valeurs par défaut de Solr pour cette classe Java.
IV-A-2-3. Exemple de dĂ©claration de champs▲
Les types (nœuds fieldType) montrés plus haut en exemple sont à répartir de la manière suivante dans les champs (nœuds field) de notre schéma :
| Type | Champ |
|---|---|
| rawText | productNameEnDisplay |
| rawText | productNameFrDisplay |
| grammedText | productNameEnAutoComplete |
| grammedText | productNameFrAutoComplete |
| englishText | productNameEnSearch |
| frenchText | productNameFrSearch |
| rawText | manufacturerNameDisplay |
| grammedText | manufacturerNameAutoComplete |
| englishText | manufacturerNameEnSearch |
| frenchText | manufacturerNameFrSearch |
Ainsi, nous pouvons effectuer nos recherches sur le champ productNameFrSearch ou productNameEnSearch suivant la langue de notre utilisateur, et afficher en réponse le nom canonique du produit (non altéré) dans la même langue. Voici les définitions de champs pour notre schéma :
<field name="uuid" type="string" stored="true" required="true"/>
<field name="productNameEnDisplay" type="rawText"/>
<field name="productNameFrDisplay" type="rawText"/>
<field name="productNameEnAutoComplete" type="grammedText"/>
<field name="productNameFrAutoComplete" type="grammedText"/>
<field name="productNameEnSearch" type="englishText"/>
<field name="productNameFrSearch" type="frenchText"/>
<!-- Un nom de constructeur n'est pas traduisible
il n'y a donc pas de version internationalisée -->
<field name="manufacturerNameDisplay" type="rawText"/>
<field name="manufacturerNameAutoComplete" type="grammedText"/>
<!-- Un utilisateur peut cependant chercher
un nom de constructeur dans sa langue favorite -->
<field name="manufacturerNameEnSearch" type="englishText"/>
<field name="manufacturerNameFrSearch" type="frenchText"/>
<field name="allEnAutoComplete" type="grammedText"/>
<field name="allFrAutoComplete" type="grammedText"/>
<field name="allEnSearch" type="englishText" multiValued="true"/>
<field name="allFrSearch" type="frenchText" multiValued="true"/>IV-C. Finaliser le schĂ©ma▲
Il nous reste deux éléments à configurer : les valeurs par défaut et les copies de champs.
<!-- Valeurs par défaut -->
<uniqueKey>uuid</uniqueKey>
<defaultSearchField>allFrSearch</defaultSearchField>
<!-- Les versions localisées du nom de produit sont copiées
dans les champs localisés -->
<copyField source="productNameEnDisplay" dest="productNameEnAutoComplete"/>
<copyField source="productNameFrDisplay" dest="productNameFrAutoComplete"/>
<copyField source="productNameEnDisplay" dest="productNameEnSearch"/>
<copyField source="productNameFrDisplay" dest="productNameFrSearch"/>
<!-- La version internationale du nom de constructeur est copiée
dans les champs, localisés ou non -->
<copyField source="manufacturerNameDisplay" dest="manufacturerNameAutoComplete"/>
<copyField source="manufacturerNameDisplay" dest="manufacturerNameEnSearch"/>
<copyField source="manufacturerNameDisplay" dest="manufacturerNameFrSearch"/>
<!-- Les versions localisées et internationales des noms sont copiées
dans les champs, localisés ou non -->
<copyField source="productNameEnDisplay" dest="allEnSearch"/>
<copyField source="productNameFrDisplay" dest="allFrSearch"/>
<copyField source="manufacturerNameDisplay" dest="allEnSearch"/>
<copyField source="manufacturerNameDisplay" dest="allFrSearch"/>Le nœud defaultSearchField n'est pas obligatoire mais il permet de simplifier les tests. Par ailleurs, sachez que le fichier solrconfig.xml permet de définir cette valeur pour chaque requestHandler. Nous aborderons cela dans un chapitre ultérieur.
Une application typique peut utiliser un champ de différentes manières : recherche, affichage, tri, facettes, surbrillance etc. Sachant que les meilleures combinaisons d'attributs pour ces différents cas d'utilisation sont différentes, il est préférable de définir plusieurs versions de chaque champ (chacune optimisée pour un cas d'utilisation) et d'avoir recours à copyField pour faciliter la population de l'index.
IV-D. Tester le schĂ©ma▲
Solr dispose d'un outil bien pratique pour vérifier que nos types fonctionnent comme prévu : l'analyseur de champs (field analysis). Le lien se trouve dans l'interface web d'administration de votre noyau ou bien directement via l'URL suivante :
http://localhost:8080/solr/CORENAME/admin/analysis.jsp
Le principe est de sélectionner "type" dans la liste déroulante, puis de saisir le nom du type à tester dans la première case de saisie. Les deux autres cases de saisie permettent de simuler une valeur indexée par ce type et une valeur cherchée par un utilisateur pour ce type. Prenons pour exemple notre type "frenchText" destiné aux recherches. Le synopsis de cet article servira de texte indexé, et les mots "manipuler du texte" feront office de termes recherchés. Pour le moment, la seule option qui nous intéresse est "highlight matches" afin de savoir si Solr a pu trouver notre mot dans le texte indexé :
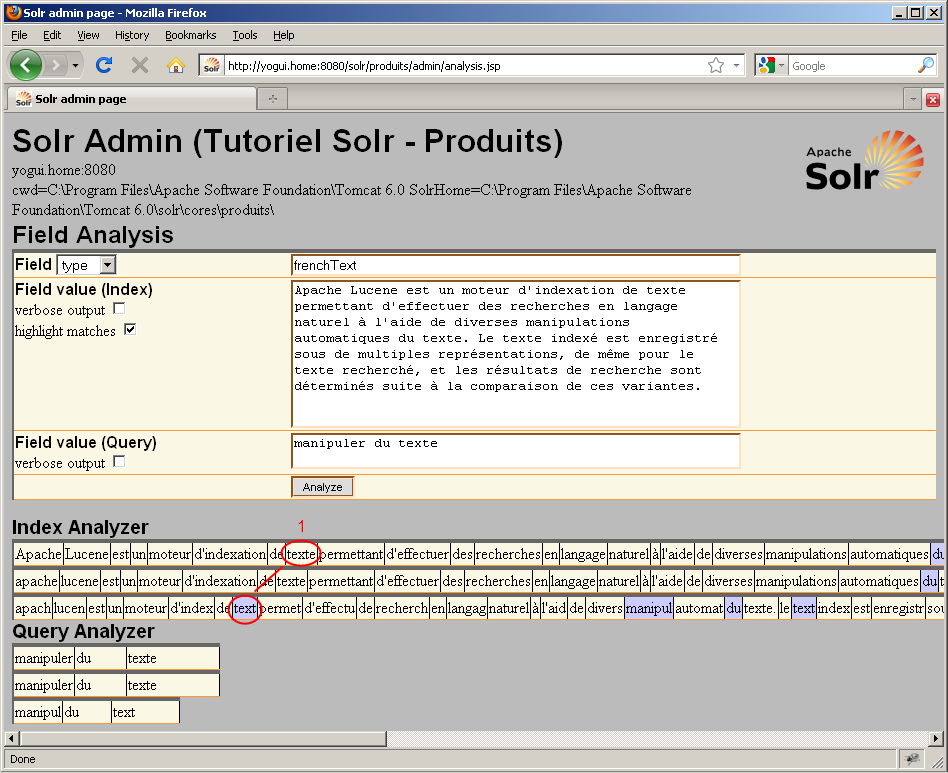
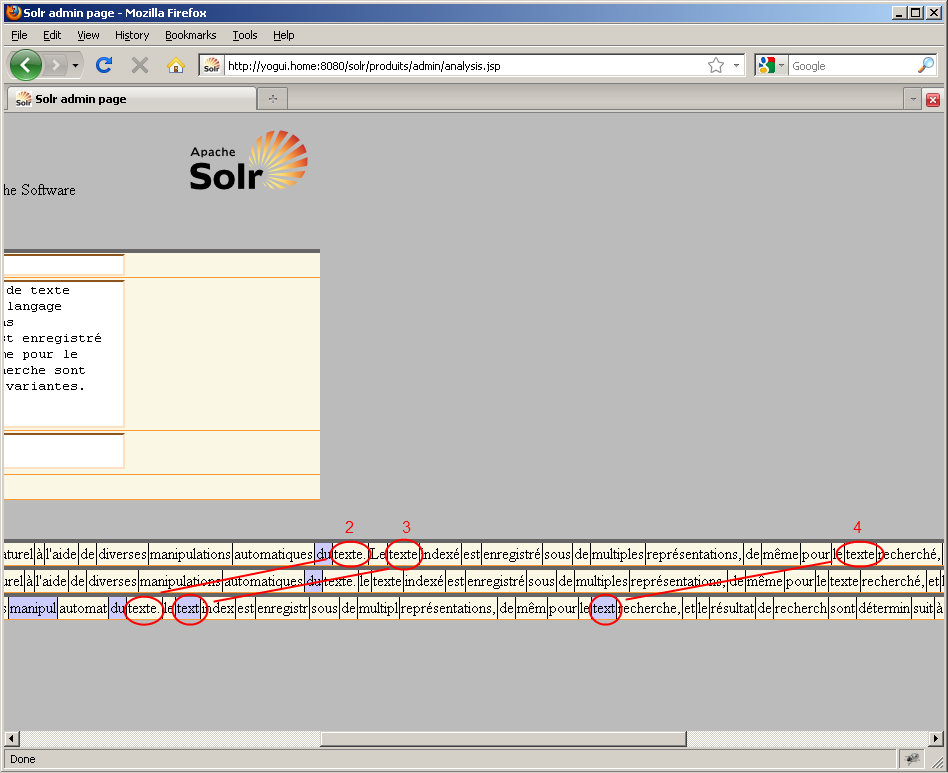
Nous voyons ici que Solr effectue trois manipulations sur notre texte de recherche (il y a trois lignes sous "Query Analyzer") ainsi que sur notre texte indexé (il y a trois lignes sous "Index Analyzer"). De plus, Solr nous montre en gris les correspondances de valeurs qu'il a pu trouver dans le texte indexé.
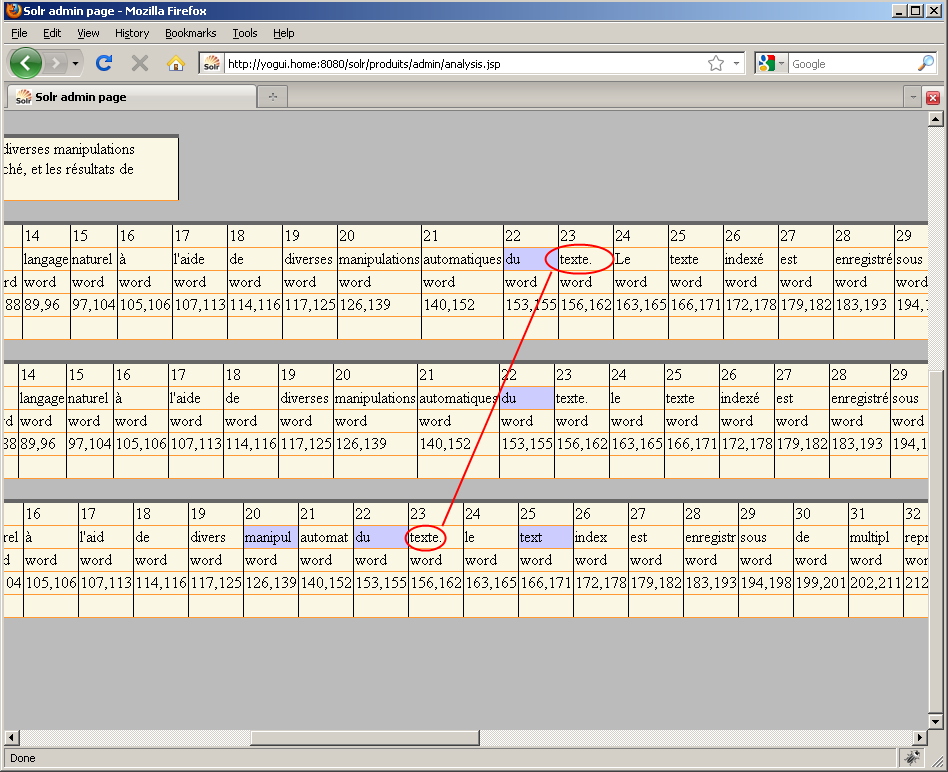
Pour un premier résultat, c'est assez engageant car nous avons effectivement pu trouver tous les termes recherchés. Cependant, un problème apparent dans la copie d'écran ci-dessus est que l'une des occurrences du mot "texte" ne figure pas dans les cases en gris, ce qui signifie que Solr ne l'a pas correctement identifiée. Solr a pu faire correspondre trois occurrences du mots "texte" dans le paragraphe indexé, au lieu des quatre occurrences que nous attendions. Notre configuration actuelle est donc un bon début mais elle n'est pas suffisamment efficace. Nous allons utiliser les options de l'outil Field Analysis pour déterminer la cause du problème.
Activons maintenant l'option "Field value (Query) / verbose output" :
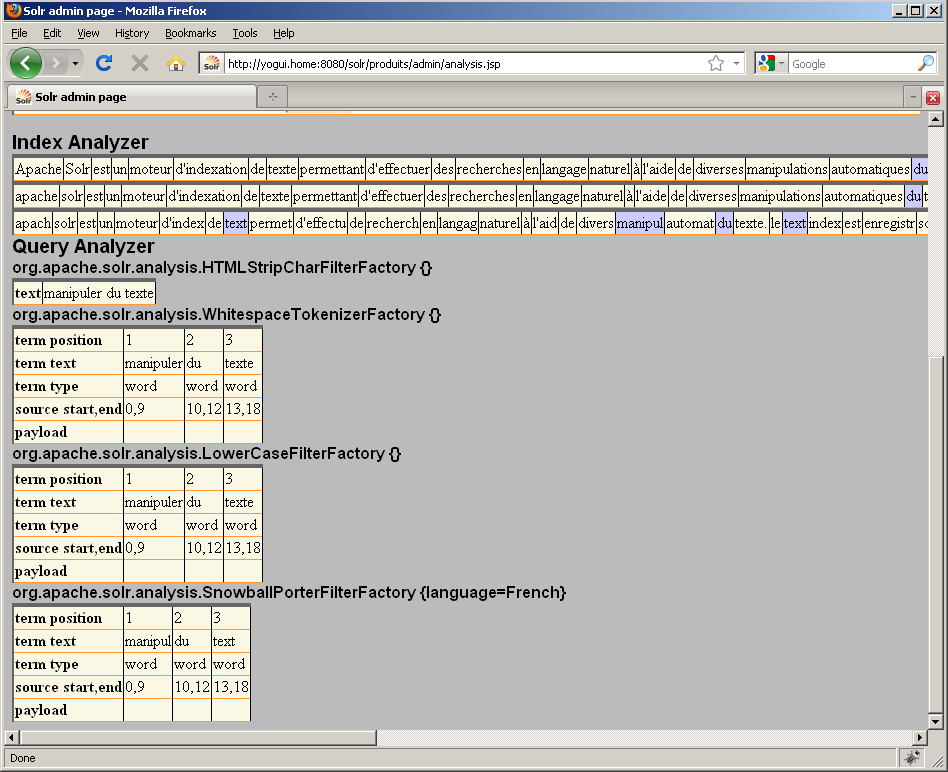
Nous comprenons maintenant que les manipulations de l'index et de la recherche sont dues aux classes Java chargées dans notre fieldType : solr.HTMLStripCharFilterFactory, solr.WhitespaceTokenizerFactory, solr.LowerCaseFilterFactory et solr.SnowballPorterFilterFactory. Après chacune de ces classes, de nouvelles variantes de l'index et de la chaîne de recherche sont affichées dans l'analyseur. Sans l'option "verbose", seuls les résultats du tokenizer et des filter sont affichés ; l'option "verbose" permet d'afficher également le résultat du charFilter.
Si nous activons maintenant l'option "Field value (Index) / verbose output", nous voyons le nom du filter duquel le terme "texte." (en position 23 dans "manipulations automatiques du texte.") ne sort pas comme les autres occurrences du mot "texte" : il s'agit du filter "SnowballPorter" en charge de la racinisation, probablement à cause du point résiduel à la fin du mot :
Si notre supposition concernant la cause du problème est correcte, alors le coupable est probablement le tokenizer. Rappelons-nous que nous avons choisi la classe solr.WhitespaceTokenizerFactory pour découper le type frenchText, or elle n'est peut-être pas adaptée. Essayons de remplacer cette classe par un tokenizer plus agressif, par exemple solr.StandardTokenizerFactory :
<fieldType name="frenchText" class="solr.TextField" positionIncrementGap="100">
<analyzer>
<charFilter class="solr.HTMLStripCharFilterFactory"/>
<tokenizer class="solr.WhitespaceTokenizerFactory"/>
<filter class="solr.LowerCaseFilterFactory"/>
<filter class="solr.SnowballPorterFilterFactory" language="French"/>
</analyzer>
</fieldType><fieldType name="frenchText" class="solr.TextField" positionIncrementGap="100">
<analyzer>
<charFilter class="solr.HTMLStripCharFilterFactory"/>
<tokenizer class="solr.StandardTokenizerFactory"/>
<filter class="solr.LowerCaseFilterFactory"/>
<filter class="solr.SnowballPorterFilterFactory" language="French"/>
</analyzer>
</fieldType>
Afin que la nouvelle configuration soit prise en compte, pensez à redémarrer Tomcat ou à charger l'URL suivante :
http://localhost:8080/solr/admin/cores?core=CORENAME&action=reload
Relançons maintenant le même test :
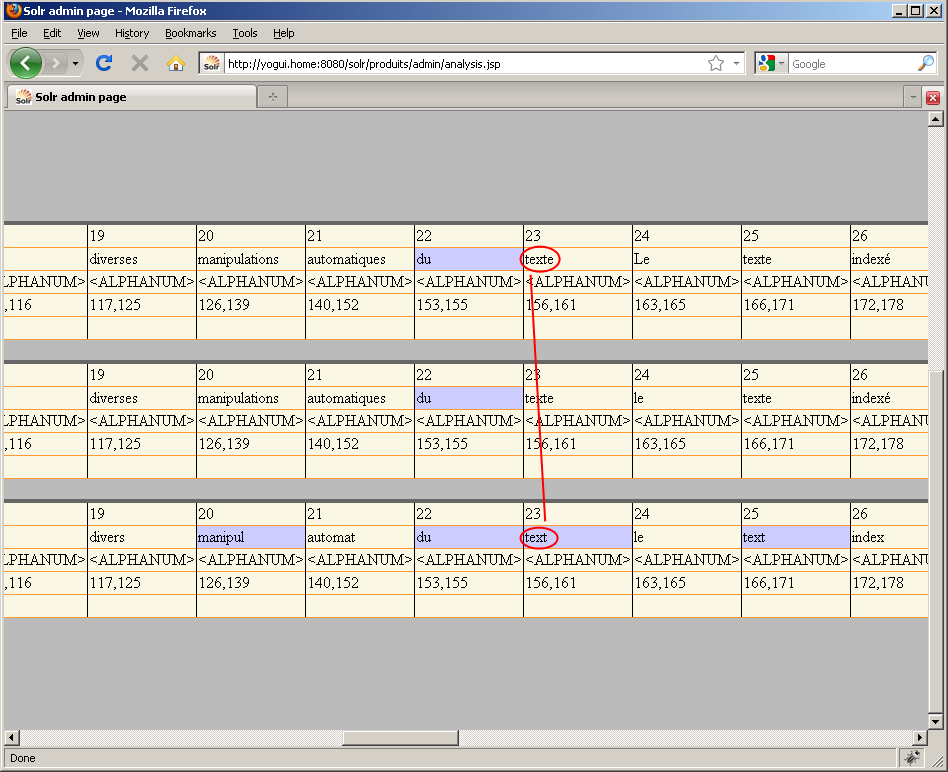
Cette fois, le texte est mieux découpé car la ponctuation n'est plus comprise dans les termes. Dans Solr, un tokenizer associe une typologie à chaque terme : avec solr.WhitespaceTokenizerFactory, cette typologie était simplement "word" ; avec solr.StandardTokenizerFactory, cela peut être "ALPHANUM", "ACRONYM", "APOSTROPHE" etc. Cette typologie est utile si vous avez choisi un dérivé de StandardFilter dans au moins l'un des filter utilisés pour ce fieldType (ce qui n'est pas notre cas ici).
- testez vos types avec des requêtes légitimes de vos utilisateurs pour voir le comportement de Solr ;
- modifiez votre schéma en conséquence ;
- redémarrez Tomcat pour prendre en compte la nouvelle configuration ;
- retour au #1 jusqu'à obtention d'un schéma satisfaisant (il y aura toujours des cas particuliers pour faire mentir votre schéma).